
Demystifying NPUs: Questions & Answers
Let's answer some 'what', 'why' and 'hows' for the Neural Processing Unit.


‘Most exciting moment’ since birth of WiFi: chipmakers hail arrival of AI PCs
Enthused the headline in the Financial Times last week. The subtitle heralded a forthcoming contest between major chip designers to convince computer makers to adopt their designs in these ‘AI PCs’.
Intel, AMD, Qualcomm and Nvidia battle to get their processors into next wave of artificial intelligence-enabled computers
And alongside the ‘AI PC’, the Neural Processing Units (or NPUs) that are a key component in these computers, are getting lots of coverage. Intel has just announced its ‘Lunar Lake’ processors that includes an upgraded NPU. Outside of the ‘PC’ world, Apple announced an upgraded NPU a few weeks ago in the M4 Chip that powers the latest iPad Pro, with more expected at WWDC this week.
However, the overwhelming impression I get from discussions of AI PCs and NPUs is one of confusion. So this post aims to remove some of the mystery through a series of questions and answers. It’s more of a ‘shallow paddle’ than a ‘deep dive’ but provides essential background for future discussion of NPUs.
I have to admit to being a little bit of an AI sceptic. It’s hard, though, not to be quite excited at the prospect of a new and powerful hardware addition to our computers.
We’ll start, as is only right, with the silicon, in the shape of the NPU.
What is an NPU?
Microsoft produced a short video to try to answer this question a few weeks ago:
Alongside some less-than-helpful headlines: “Powerful new possibilities” and “A new AI era begins” the video set out that NPUs are about doing tasks such as “recognizing voice commands” and “creating visual content” and that NPUs bring more performance and power efficiency to these tasks.
I know that this won’t be enough for Chip Letter readers so we’ll supplement this with more Q&As that add more detail.
Let’s restate the answer to the most basic question first. What is an NPU?
An NPU is a specialized piece of hardware that’s designed to undertake certain AI or machine learning-related tasks. More specifically, it is specially designed to perform calculations needed for ‘inference’ or the application of an already trained deep learning model to generate useful results for the user.
Why ‘Neural Processing Unit’?
Deep learning inference uses neural networks to generate results, hence the ‘Neural’ in ‘Neural Processing Unit’.
What is an AI PC?
Intel’s website defines an “AI PC” with:
AI PCs use artificial intelligence technologies to elevate productivity, creativity, gaming, entertainment, security, and more. They have a CPU, GPU, and NPU to handle AI tasks locally and more efficiently.
So its any PC with an NPU? Yes, but there is a qualification. If you want to run AI-based software, such as the latest tools from Microsoft then your NPU needs to have a certain level of performance. Microsoft has added its branding to these new PCs by introducing the term ‘Copilot+PC’.
Copilot is Microsoft’s Windows AI assistant. A Copilot+PC is a PC with an NPU that meets Microsoft’s minimum performance requirements to support the full set of Copilot capabilities. We’ll cover what this means in practice later on.
Isn’t the NPU just like a TPU?
Regular readers will recognize that the NPU sounds much like Google’s first Tensor Processing Unit (or TPU) whose origins and architecture we’ve already discussed in some detail. NPUs and Google’s (first) TPU have a lot in common, both in what they are used for (machine learning inference) and in the technology used; all include hardware specialized to accelerate matrix multiplications.
If you want to know more about what the TPU does and how it does it then I’d recommend revisiting the earlier post on the TPU’s architecture.
Google's First Tensor Processing Unit : Architecture

… we say tongue-in-cheek that TPU v1 “launched a thousand chips.” In Google’s First Tensor Processing Unit - Origins, we saw why and how Google developed the first Tensor Processing Unit (or TPU v1) in just 15 months, starting in late 2013. Today’s post will look in more detail at the architecture that emerged from that work and at its performance.
There are also some key differences though, between most NPUs and that first Google TPU, which we’ll cover later in this post.
NPUs & TPUs! Isn’t this naming confusing?
Yes!
TPU has become Google’s name for all its cloud AI accelerator chips including its later designs that perform training as well as inference. Google has also used TPU as the name for the NPU in its Pixel smartphone. Elsewhere on the cloud, other firms use a variety of names for their specialized AI accelerators, adding to the confusion.
Thankfully, the term NPU is being more consistently applied - by Intel, Apple, Qualcomm, AMD, and others - as the term for specialized inference hardware.
Where would I expect to find an NPU?
We’ve already seen that we can find an NPU in an AI PC. It’s also found in the other locations that are sometimes known as ‘the edge’ as opposed to ‘the cloud’. Or more prosaically, on your personal computer, smartphone, or ‘Internet of Things’ device.
So the NPU is a Chip?
Not usually. Unlike, Google’s TPUs, NPUs aren’t normally separate chips. Instead, they are a distinct block of circuits on a System-on-Chip, the single silicon die that contains all of the processing capacity needed to power a modern personal computer or smartphone.


When announcing the M4 chip, used in the latest iPad Pro, Apple provided a stylized image portraying the location of the NPU on the SoC silicon die. Even allowing for the approximate nature of this portrayal we can see that the NPU takes up a non-trivial part of the M4’s die.
Having the NPU on the same die as the CPU means that the NPU will be cheaper to make and more power efficient than if it was on a separate chip.
The situation with Intel - who has also provided a stylized image of the NPU on a Lunar Lake die - is a little more complex as Intel is now splitting its designs into several ‘tiles’ or ‘chiplets’. The NPU sits close to Lunar Lake’s CPUs on the design’s ‘compute tiles’ - separate silicon dies that are assembled with other tiles to provide the same functionality as an SoC.

We’ll discuss whether your actual PC or smartphone has an NPU a little later.
Will there be discrete NPUs just as there are discrete GPUs?
If you’re a PC gaming enthusiast there is a good chance that you have a ‘discrete’ GPU from Nvidia or AMD that sits on a separate chip and provides more graphics performance than an ‘integrated’ GPU on the main SoC can manage. If I want more AI performance will I be able to buy a ‘discrete’ NPU?
There is no technical reason why there shouldn't be discrete NPUs. However, discrete GPUs can provide enhanced AI performance if needed, and the likely limited demand for a discrete NPU means that it’s very unlikely that they will be economical to produce.
There are some exceptions to this and one good example is the dedicated NPU add-on board (or ‘hat’) for the Raspberry Pi 5 available from Hailo and demonstrated in this video from Jeff Geerling.
In this screenshot from this video, we can see the Hailo board doing a good job of identifying objects in Jeff’s video camera.
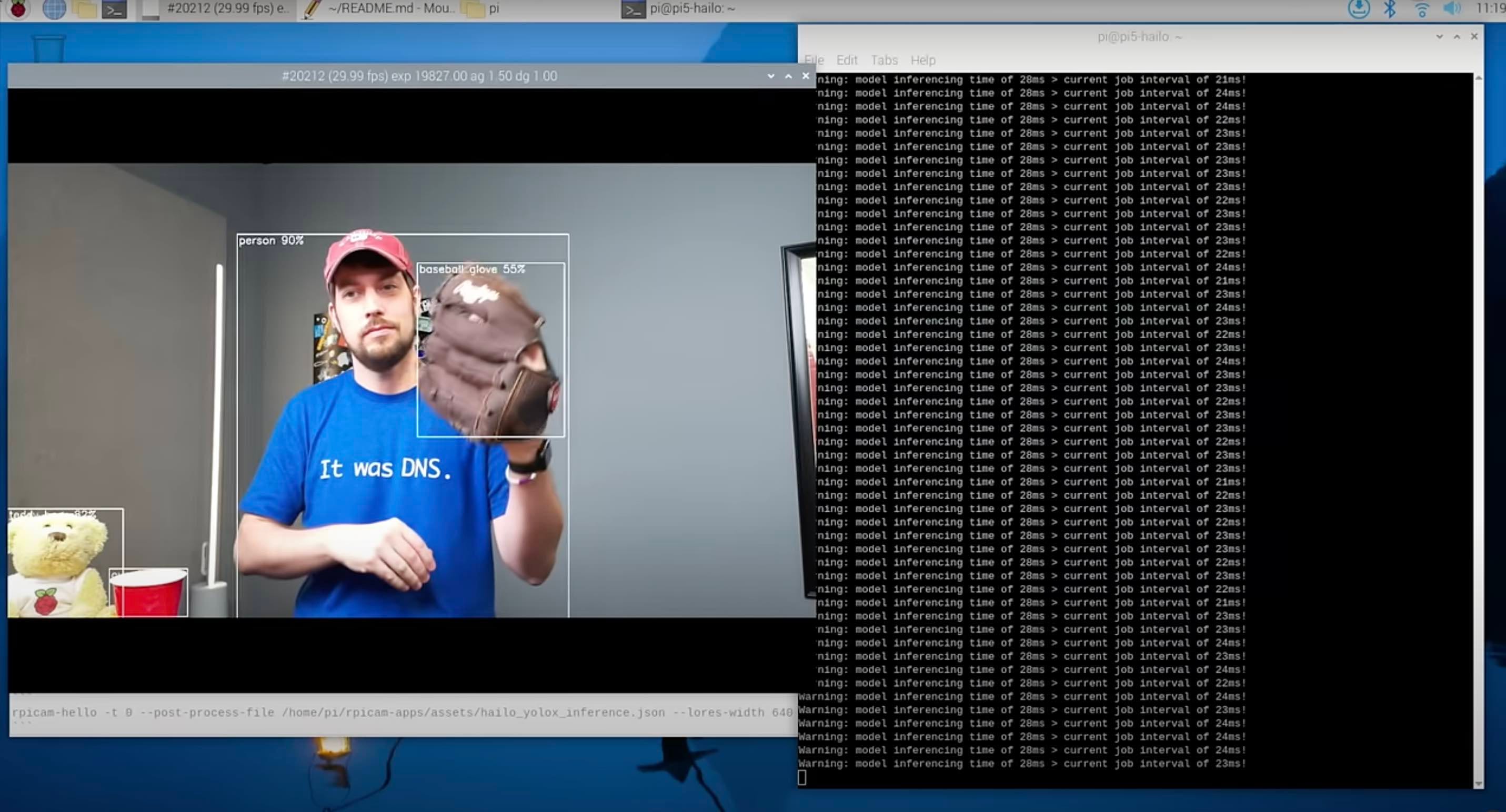
The Hailo is a great way of giving the Raspberry Pi better AI capabilities.
Why would anyone want an NPU?
This is great, but inference can be done by any standard ‘general purpose’ CPU. However, having a specialized piece of hardware has three main advantages when performing the calculations needed for inference. It can:
Speed them up, and;
Reduce the amount of power they need, and;
Free up the CPU to perform other tasks.
Faster inference means a more responsive PC or smartphone and lower power means better battery life on mobile devices, both of which are important in improving user experience. These improvements may make machine learning practical where otherwise it might have, for example, been too slow to be useful.
I’m not using AI on my Personal Computer or Smartphone. Why do I need an NPU?
You may not be using applications that identify as using AI but there is a very, very high probability that you are that you are already using machine learning inference routinely. It’s providing features that we take for granted in applications that we use every day, such as:
Facial and voice recognition;
Blurring the background in photo editing and Zoom calls;
Predictive typing on smartphone keyboards;
Optical character recognition in scanned documents.
And many, many more!
In all of these examples, NPUs have the potential to improve the user experience.
So if I use ChatGPT then can I speed things up using an NPU?
Most well-known and popular Large Language Models (LLMs) like ChatGPT and its competitors use hardware in the cloud to perform inference and don’t (yet) use NPUs on your PC or smartphone.
However, with the right software, there is no reason why an NPU shouldn't be used to accelerate inference for LLMs running ‘locally’ on your PC.
GPUs can perform inference. I have a GPU. Why do I need an NPU?
Well known LLMs such as ChatGPT often use GPUs from Nvidia to perform inference in the cloud. And your PC or smartphone will always include a GPU.
Nvidia has been successfully turning its GPUs into devices that are highly effective accelerators for machine learning training and inference. It has done this through the development of both a high-quality software ecosystem (centered on CUDA) and through the refinement of its hardware, including adding specialized tensor matrix multiplication units to its GPUs. Other GPU designers have either not done this or have been much less effective in doing so.
Plus the GPU on your PC or smartphone is already needed to perform its original function: drawing images on your display. What happens if your device needs to draw some complex graphics and perform machine learning at the same time? Having a separate NPU removes this potential contention.
Why not build NPU calculation hardware into the CPU or GPU?
One option would be to build extra capability into either the CPU or GPU to provide the ability to accelerate these machine-learning tasks. This might be extra processing capacity for a GPU, some specialized matrix multiplication units, and maybe some new instructions on the CPU.
This is possible. The latest versions of CPU designs do include new instructions that can be used to accelerate machine learning inference. Recent discrete GPUs from Nvidia and AMD have tensor processing unit hardware that accelerates matrix multiplication operations in the GPU.
However, there are good reasons why this may not be the best option and why a separate NPU block is likely to be preferable:
The nature of inference, with its need to perform a large number of known and predictable mathematical operations is fundamentally different from the tasks that CPUs are designed to perform. CPUs even with extra instructions are just not going to be as efficient as an NPU that is designed from the outset for these tasks;
The nature of GPUs makes them better suited to this but they are still likely to fall short of what is possible with an NPU;
Having NPUs in a separate ‘block’ makes it possible to turn the block off completely or to run it at a lower clock frequency than the CPU or GPU and so save power without adversely affecting performance on other tasks.
The NPU is a separate hardware ‘block’ on the SoC. What does this mean in practice?
A program on the CPU decides that it wants to run a particular machine-learning task. It then needs to communicate to the NPU what calculations it needs the NPU to perform. The CPU will also need to transfer data to the NPU and get access to the results generated when the NPU has finished its calculations.
This all means that there needs to be a communication channel between the CPU and the NPU. The NPU will also need some processing capability to control that communication with the CPU, to deal with memory accesses, and to coordinate and control the calculations, the matrix multiplications and the application of activation functions, that are the NPU’s primary role.
So what does NPU hardware look like?
Each different NPU design has a subtly different architecture. We’ll illustrate with one example, the NPU on the Lunar Lake processors from Intel, which is portrayed in this stylized schematic from Intel:
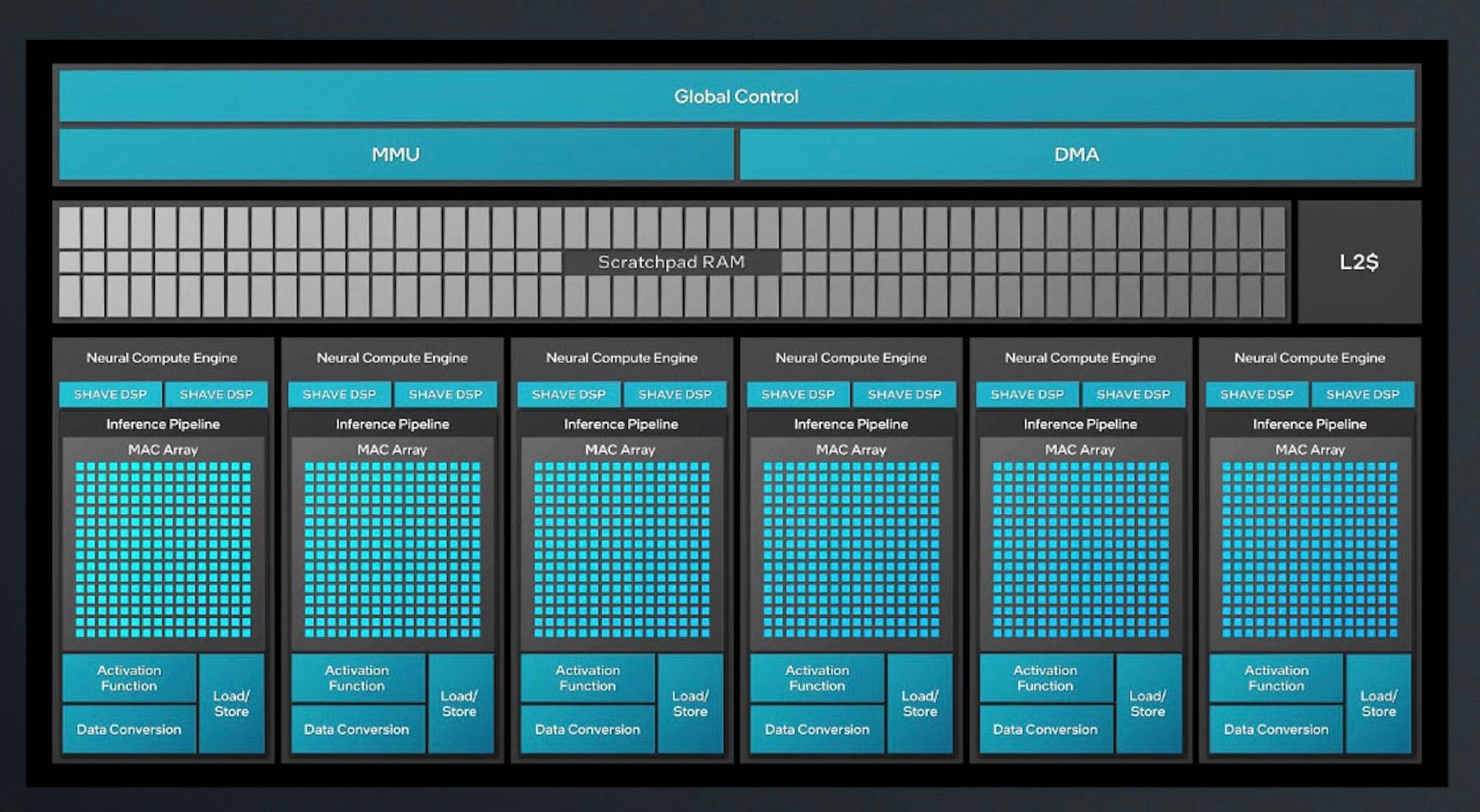
Starting from the top down we can see (in italics if this is Intel-specific terminology)
A global control unit (a processor) that controls the overall operation of the NPU including communication with the CPU.
MMU / DMA - Units to control memory access.
Scratchpad RAM/L2$ - RAM storage for the NPU and cache memory.
Six Neural Compute Engines, each with:
Two SHAVE DSPs (Digital Signal Processors). SHAVE is the name of Intel’s DSP. We don’t need to explain what a DSP is here but these handle many of the ‘non-matrix multiply’ computations that the NPU needs.
A MAC (for ‘Multiply ACumulate’) array. This is just another word for a matrix multiply unit as seen in Google’s first TPU.
Activation function - this is hardware to perform the activation functions that are needed by Deep Learning models.
Data Conversion - this performs the conversion of data between different numerical formats.
Load / Store - hardware to access data and store results as required.
It’s notable that Lunar Lake, in common with almost all other NPU designs, has multiple sets of matrix multiply hardware, one in each of the ‘Neural Compute Engines’. This is in contrast with the single large unit we saw in Google’s first TPU. Having multiple units gives the NPU more flexibility and makes some aspects of the design more straightforward to implement.
I should emphasize that this is just Intel’s NPU implementation. NPUs from other firms can and do have - sometimes radically - different architectures.
How do I program NPUs?
As the schematic of Lunar Lake above shows, NPUs are quite complex beasts. Their separation from the CPU means that they need drivers - software provided by the manufacturer to allow the operating system to control them and APIs (Application Programming Interfaces) so that high-level programming languages can use them.
Most of the low-level details of how they are programmed - instruction sets and so on - are usually hidden from the programmer and may not even be documented outside of the firm that designs them.
This has the advantage for designers that they can change details from one version to the next whilst maintaining software compatibility between versions.
How do we measure the performance of NPUs? What’s this TOPS?
TOPS stands for ‘Trillion (floating point) Operations Per Second’. One of the main tasks of the NPU is to perform the mathematical operations - multiplication and addition - needed for matrix multiplication. So counting the number of these operations that an NPU performs per second is a convenient way to measure the performance of an NPU. TOPS values are often quoted for the leading NPUs.
Indeed, Microsoft quotes a minimum of 40 TOPS for an NPU to be good enough to qualify for use in a Copilot+PC.

However, as always, a single ‘TOPS’ value doesn’t capture the full range of factors that affect the performance of an NPU. The speed of memory access or of communication with the host CPU will, for example, also be significant factors affecting the performance of an NPU.
Does my particular PC or Smartphone have an NPU?
In short, if you have a very recent high-end smartphone you likely have an NPU on it but it’s unlikely that your PC has an NPU unless it’s from Apple.
Let’s explain more why this is likely to be the case by first looking at a small sample of major smartphone/SoC brands:
Apple
Apple added NPUs to the:
A14 Bionic SoC in the iPhone 12 and 10th generation iPad in 2020.
M1 SoC in the first Apple Silicon Macs and the iPad Pro in 2020.
All subsequent generations of iPhone, iPad, and Mac have had (enhanced) NPUs in their designs.
Qualcomm (used by Samsung and others)
Qualcomm first added the ‘Hexagon Tensor Accelerator’ to the Hexagon NPU in the Snapdragon 855 in 2018. The Snapdragon 855 was used in the Samsung Galaxy S10 and other contemporary Samsung models as well as high-end smartphones from many other manufacturers.
See here for a fuller list of the smartphones powered by the Snapdragon 855.
Google Tensor is a series of ARM64-based system-on-chip (SoC) processors designed by Google for its Pixel devices. (Wikipedia).
Confusingly Google uses the name Google Tensor for the whole SoC in its most recent Pixel smartphones. The actual NPU in the first of these phones - launched at the end of 2021 - is branded ‘Edge’. Later Pixel phones have had upgraded NPUs.
So NPUs have been around for a while on higher-end smartphones. What about PCs?
AMD
AMD first shipped an NPU using its XDNA architecture in PCs sold in 2023. The second generation XDNA 2 architecture was announced by Lisa Su at 2024 Computex and will ship later this year.

Intel
NPUs were first added to Intel’s Meteor Lake laptop processors that first shipped at the end of 2023.

An upgraded Intel NPU for the latest Lunar Lake processors was announced at Computex 2024 last week and these will ship later this year.
Qualcomm
You might be surprised to see Qualcomm listed as a PC chip designer. However, in some ways, Qualcomm has ‘stolen a march’ on the x86 based PC incumbents, Intel and AMD, with its Snapdragon X Elite SoCs, which are used in the latest Surface laptops from Microsoft itself.
And of course no AI PC launch would be complete without its own promotional video and the Snapdragon X Elite is no exception. We can see that the new Snapdragon meets the minimum TOPS requirement for a Copilot+PC!

We can’t leave this section though without mentioning one final company.
Nvidia
Nvidia doesn’t have an NPU. Seriously, Jensen, what have you been doing?
Should I upgrade my PC to get an NPU?

Chip and PC designers would answer this with a resounding yes of course. We’re entering ‘The AI Era’ you need the latest AI PC!
Well, they would say that, wouldn't they?
As we’ve seen higher-end smartphones have had NPUs for a few years now and so it’s quite likely that your phone already has an NPU; the latest version may have an upgraded NPU that offers better performance.
For PCs, it’s a different matter. Unless you have a very recent high-end laptop from the latter part of 2023 then you probably won’t have an NPU.
Does this matter?
An older PC won’t support the full set of capabilities that Microsoft offers in Copilot. However, whether this matters to you will depend on how valuable you see those capabilities. I personally don’t see a ‘killer app’ that would persuade me to upgrade. If you are a heavy user of a creative package like Photoshop that could make heavy use of generative AI then you may have a different perspective.
Microsoft’s own launch event shows the capabilities that Microsoft itself is headlining as the key attractions of Copilot+PCs.
Finally, don’t rush out and buy a PC today to get an NPU. It won’t have the latest NPU and it is probably worth waiting to see how the market and in particular the contest between Intel, AMD, and Qualcomm works out.
This has been a high level dash through the world of NPUs and AI PCs.
In the next post, for premium subscribers, we’ll continue with more detail on these NPU architectures, including their history and more on the latest versions. You can upgrade your subscription to receive these and also help support The Chip Letter at the same time using the button below.
Finally, I hope you found this post useful. Premium subscribers can comment, and maybe suggest some further questions, after the paywall.