


Writing-up my first post on the origins of RISC (coming very soon!) has meant taking a look at the earlier IBM S/360 mainframe architecture.
S/360 and it’s successors has been the mainstay of IBM’s mainframe business for over fifty years. IBM invested over $5bn (or $40bn adjusted for inflation) in developing the S/360 in the 1960s. It’s driven many more tens of billions in sales in the decades that have followed.
What’s really surprising about S/360 is that an architecture from an era with so many fewer transistors had so much complexity.
Let’s take one example instruction: the ‘EDIT’ instruction:

Yes, this is all done by a single assembly language instruction.
Some really important systems were written directly in S/360 assembly. And some of them still have hand-written S/360 assembly language in there!

I believe that rewriting that S/360 assembly language is one of the barriers to reform of the US tax system.
The ‘Programmer’s Introduction to IBM S/360 Assembly Language’ helpfully has an example of hand-written S/360 assembly. And when I say hand-written that’s exactly what I mean.

I know that writing things down can often help understanding but I think I’ll stick to Visual Studio Code.
S/360 instructions were implemented in microcode. Ken Shirriff has built an emulator that reproduces that microcode execution (picture below).
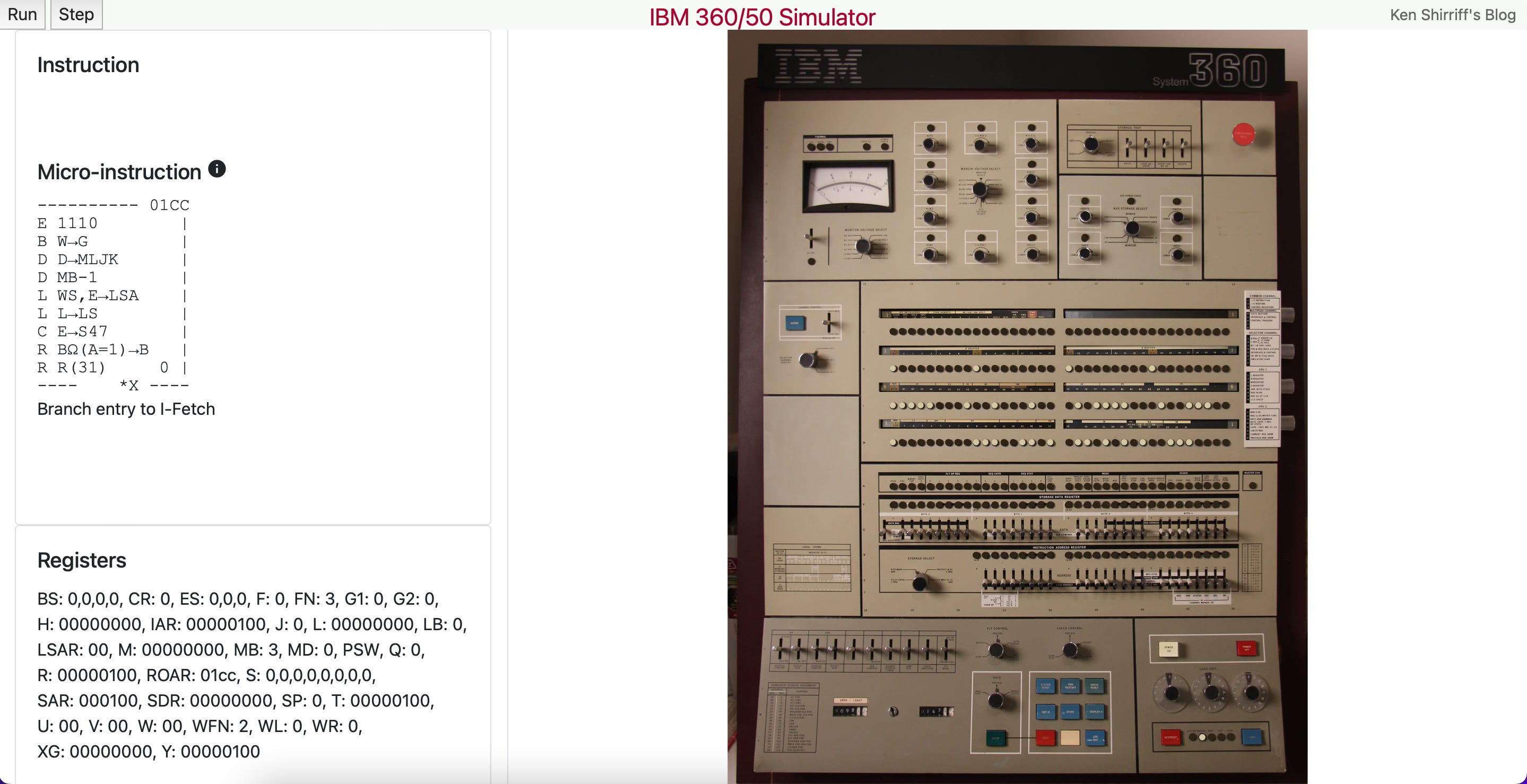
All this complexity had a performance penalty. Already, at the time of the development of S/360, some at IBM thought that this wasn’t the best approach. As we will see, this led to the development of RISC architectures at IBM.
The S/360 architecture lives on in modern IBM mainframes. We should probably be thankful though that it never made it into our PC’s, servers or smartphones. And that we’re not still writing out assembly code by hand.
Have a great weekend everyone and look out for out first article on RISC over the weekend.
Image Credits
Ik T from Kanagawa, Japan
CC BY 2.0 <https://creativecommons.org/licenses/by/2.0>
via Wikimedia Commons
OMG, seeing that form makes it so obvious why assemblers assume labels are in the leftmost column, why mnemonics have to have some prefixed whitespace, and why disassembles add whitespace to line up labels, opcodes, and comments. All of that comes directly from assembly being written on a paper spreadsheet!