
Deep Thought, Deep Learning and the World's Total Computing Resources
What does the AI boom mean for the aggregate of the world's accessible computing resources?

In this post we look at the impact that investment in AI hardware is having on the world’s total computing capabilities.
Deep Thought: I speak of none but the computer that is to come after me. The computer whose merest operational parameters, I am not worthy to calculate. Yet, I will design it for you. A computer which can calculate the answer to the ultimate question. A computer of such infinite and subtle complexity that organic life itself shall form part of its operational matrix and you yourselves shall take on new forms and go down into the computer to navigate its 10,000,000 year program.
Yes, I shall design this computer for you and I shall name it also unto you.
And, it shall be called the EARTH.
In Douglas Adam’s The Hitchhiker’s Guide to the Galaxy, the Earth is a giant supercomputer, designed by another supercomputer, ‘Deep Thought’, and created to understand what the "Ultimate Question of Life, the Universe, and Everything" really is.
The earth as a computational resource.
It’s not quite what Douglas Adams meant, but with millions of computers linked together we can think of them all as a single computing resource. But, how powerful is that resource? What do we find if we assess the total amount of accessible computing power available on Earth?
And then, how will this be changed by the current AI boom? We know that we are adding a lot of ‘compute’ but is it a factor of 10 increase? Or a doubling? Or much less? In this post we’ll try to find out.
There are two reasons for asking this question. First, it helps give a sense of perspective and scale. When we hear a firm has acquired 20,000 Nvidia H100s, I personally have no sense of what this means, for example, relative to existing installed computing resources.
Second, it’s possible that the current boom will lead to ‘overbuilding’. In Sequoia Capital’s AI’s $200B Question :
During historical technology cycles, overbuilding of infrastructure has often incinerated capital, while at the same time unleashing future innovation by bringing down the marginal cost of new product development. We expect this pattern will repeat itself in AI.
…
So the $200B question is: What are you going to use all this infrastructure to do? How is it going to change people’s lives?
If there is overbuilding then it’s interesting to understand the scale of that overbuilding. If the AI boom doesn’t work out then perhaps we can use all those computers for other things?
Some ground rules. We’re going to exclude consumer devices from the assessment. Whilst in theory it would be possible to use the power of billions of smartphones, tablets and consumer PCs to solve problems, in practice it’s likely to be too difficult. And their users may have other ideas!
We’ll initially focus on supercomputers which, with their emphasis on floating point computation, are the most direct comparator for the kind of computational power being added in the current AI boom. That means we can take data from the TOP500 list of the most powerful computers in the world.
We’ll also concentrate on Float64 or FP64 performance. These are floating point operations that use 64-bits of data. This is the most accurate of the commonly used floating point formats, and has the advantage that the data on performance is readily available across a range of computing platforms.
We’ll later bring in the ‘public cloud’, but exclude servers in ‘private’ datacenters.
Two disclaimers. First, Many of the estimates in this post are based on reasonably reliable, and publicly available data. Others are very broad estimates indeed and so should be treated with the utmost caution. If you think any are wildly off then please let me know in the comments or by replying to this email. In fact, I’d love to hear and share alternative assessments.
Second, not all FLOPS are created equal! Comparing crude headline figures on a single metric doesn’t give a realistic assessment of the relative performance of two systems, and other factors, such as memory bandwidth, may be more important in practice.
The rest of this post will have lots of large multiples of FLOPS so here is a short table to help navigate the names used.

A Very Brief History of Supercomputers
In the beginning there was only one electronic computer. In 1946, ENIAC could manage 385 floating point operations per second (or 385 FLOPS, for short).1
By 1975, Seymour Cray’s Cray-1 could manage 160 MegaFLOPS. The Cray-1 cost the equivalent of $40m in 2023. Just 100 Cray-1’s were built.

By 1993 the performance of the fastest supercomputer had increased to around 60 GigaFLOPS. From then on, the TOP500 / Our World in Data have charts that track the progress of the fastest supercomputers up to 2022.
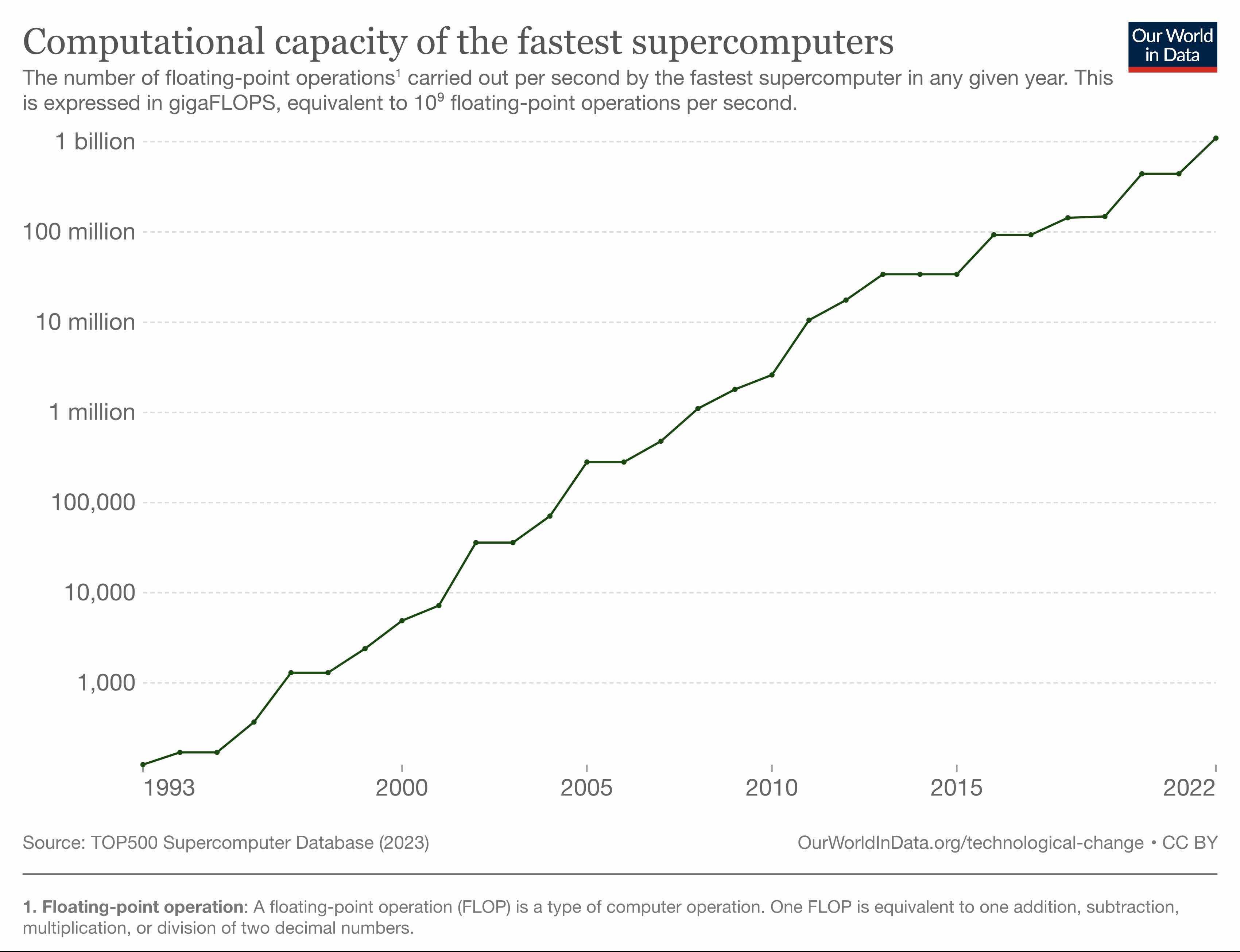
In 2023, the fastest Supercomputer in the world is Frontier, which can deliver 1.2 ExaFLOPS.
Note that for these supercomputers we are using the TOP500 ‘RMax’ measure which tests the performance of the largest problem run on the machine and not its theoretical peak performance, ‘RPeak’, which will typically be somewhat higher. For Frontier RPeak is almost 1.7 ExaFLOPS.

Frontier uses, as most ‘supercomputers’ do today, a lot of GPUs:
Frontier uses 9,472 AMD Epyc 7453s "Trento" 64 core 2 GHz CPUs (606,208 cores) and 37,888 Radeon Instinct MI250X GPUs (8,335,360 cores).
The next planned ‘exascale’ supercomputer Aurora, this time powered by Intel CPUs and GPUs, but repeatedly delayed since 2018, will deliver around 2 ExaFLOPS.

And then, El Capitan, also with 2 ExaFLOPS of performance and powered by AMD, is planned for 2024.
It’s worth emphasising that these expensive and powerful systems are built to do vital jobs. El Capitan, for example is being built to support ongoing management of the US nuclear stockpile:
DOE/NNSA is embarking on a multi-year collaboration with the selected system vendor and its subcontractors to work on non-recurring engineering and system integration to deliver El Capitan. The collaboration focuses on system engineering efforts and software technologies to assure the 2023 exascale system will be a capable and productive computing resource for the Stockpile Stewardship Program.
It’s also notable that Cray, now owned by Hewlett Packard Enterprise, has been heavily involved in the development of all these machines, almost fifty years after the Cray-1 was introduced.
The Earth’s Total Accessible Supercomputing Power
Let’s return to an assessment of Earth’s total computing resources. We’re less interested in the performance of an individual computer than in the total computational power available.
By June 2023 the TOP500 - a table of the most powerful 500 supercomputers - could deliver a total of 5.2 ExaFLOPS of performance.
Let’s try to put this into perspective:
An ExaFLOPS is 10 ^ 18 FLOPS. That’s a thousand PetaFLOPS, a million TeraFLOPs or a billion GigaFLOPS.
So 5.2 ExaFLOPS is around 650 MegaFLOPS for every person on Earth.
Or, around 30 billion Cray-1 computers.
New Compute From The ‘AI Boom’
Now, let’s consider the computational power added by the current ‘AI Boom’.
Nvidia’s ‘top of the line’ GPU, the H100, offers a minimum of 26 TeraFLOPS of FP64 performance.

Incidentally, in the Terminator 3 film, Skynet is quoted as delivering 60 TeraFlops of performance.
So couple of H100s deliver essentially the same level of performance of Skynet!
HPCWire reports that
The GPU Squeeze continues to place a premium on Nvidia H100 GPUs. In a recent Financial Times article, Nvidia reports that it expects to ship 550,000 of its latest H100 GPUs worldwide in 2023.
We’ll assume, conservatively, that all these 550,000 GPUs are H100 PCIe.
These will deliver a minimum of 550,000 x 26 TeraFLOPS or around 14 ExaFLOPS of FP64 performance.
That’s more than double the total TOP500 FP64 installed performance.
We have, of course, omitted items from both sides of the comparison so far. The existing public cloud from the existing installed base. And other AI accelerators from the ‘new’ in 2023.
For the first, let’s assume (a wild guess really) that there are 30 million servers across Amazon’s AWS, Google Cloud, Microsoft’s Azure, Alibaba Cloud and other public clouds, and they deliver 500 GigaFLOPS of FP64 per server. That’s 15 ExaFLOPS for CPUs in the public cloud.
There is also the existing installed base of GPUs. Nvidia’s previous generation A100 delivered a little less than 10 TeraFLOPS. With less demand, I think it’s not unreasonable to estimate a total of less than 10 ExaFLOPS.
So, that’s a, very rough, estimate of at most around 25 ExaFLOPS of FP64 performance for the existing public cloud.
We have excluded 2023 shipments of competing GPU’s / accelerators. Of these Google’s TPU is likely to be the device that has been deployed most widely although most are used for Google’s own services. For that reason, I’m going to assume that neither of these materially alter the comparisons. We’re also ignoring sales of Nvidia’s, last generation, A100 GPUs.
So, new Nvidia H100 compute in 2023 is likely to be at least one-half of the total FP64 capability of the existing public cloud.
How Big An Increase In Compute?
Let’s sum up. New Nvidia H100s this year seem likely to amount to more than double the world’s existing TOP500 supercomputer FP64 capability, and this is likely more than half the total FP64 capability of the existing public cloud.
New Nvidia H100s this year seem likely to amount to more than double the world’s existing supercomputer FP64 capability, and this is likely more than half the FP64 capability of the existing public cloud.
So we are adding an awful lot of compute capability, and what is more it’s dedicated to, at the moment at least, a relatively narrow set of new tasks.
And, of course, this isn’t quite the whole story …
Specialised Tensor Floating Point
The new GPUs being added today are, of course, specialised for AI capabilities.
Let’s have a look at the performance on FP32 (floating point operations using 32 bits of data) using ‘Tensor Cores’ in the Nvidia data sheet. Tensor Cores are, of course, specialised for the sort of operations that are needed for deep learning.
Now performance for each H100 jumps to 756 TeraFLOPS, an increase of almost 30x the FP64 performance.
So, if look at the number of number of floating point calculations possible, by reducing accuracy, and making the calculations less ‘general purpose’ the picture changes dramatically.
If we assume that FP32 performance is 2x that for FP64 for the existing installed base, then the comparison is roughly 400 ExaFLOPS for ‘new compute’ vs less than 50 ExaFLOPS for the installed base.
A factor of 8 increase!
This all says, of course, that these new machines really are ‘AI supercomputers’. They are designed to deliver a step change in machine learning training and inference capability, and not generic FP64 performance.
And of course this is only for 2023. If investment continues at a similar rate then we will see even more dramatic increases.
To reiterate. These are very broad estimates, so should be treated with the utmost caution. If you think any are wildly off, then please let me know in the comments, or by replying to this email.
I hope this helps to give a sense of the scale of what is happening at the moment.
Finally, a brief return to Douglas Adams and The Hitchhikers Guide. It’s amazing how prescient much of what he wrote was. The Guide itself is effectively the modern smartphone. And AI powered live translation - delivered by the power of the ‘supercomputers’ we’ve been discussing, through EarPods - is the real life implementation of Adam’s fictional ‘Babel Fish', the fish that has evolved to do automatic real-time translation.
The next post, later this week, for paid subscribers, will have more on this theme together with more data on supercomputer and on GPU performance trends.
If you value The Chip Letter,then please consider becoming a paid subscriber. You’ll get additional weekly content, learn more and help keep this newsletter going!
https://www.clear.rice.edu/comp201/08-spring/lectures/lec02/computers.shtml
You might be off on how much compute is out in the world? Digitimes reported today China thinks it has 197 exaflops installed -
"MIIT revealed in August that China's aggregate computing power reached 197 EFlops, ranked second in the world after the US. However, no details were provided regarding the scale of computing power in the United States that was being referred to. According to the 2022-2023 Global Computing Index jointly published by IDC, IEIT Systems, and Tsinghua Institute for Global Industry, the US and China are the two front runners in terms of computing power.
Source: Ministry of Industry and Information Technology of China, October 2023"
That is a lot of compute🤯