
Demystifying GPU Compute Software
Comparing Nvidia's CUDA with its competitors from AMD, Intel and others

This post looks at the major tools in the ecosystem including CUDA, ROCm, OpenCL, SYCL, oneAPI, and others. What are they? Who supports them? What is their history? How do they relate to each other?
Welcome to The Chip Letter. Today’s post is a follow-up to Demystifying GPU Compute Architectures.

That post discussed essential features of the architectures of two recent GPU designs, from Nvidia and AMD. We also briefly touched on programming GPUs with Nvidia’s CUDA and AMD’s ROCm.
This post expands on that by exploring the wider landscape of GPU programming tools available today.
This is a long post (it’s 44 pages when I print it out!) so it’s unfortunately quite likely that your browser will truncate it. So please click on the post title above to see the full version.
This post was written in March 2024, but I’ll look to provide updates so that it continues to be a useful document.
Note that this is a premium post with most of the content after the paywall. To sign up for a premium subscription just press this button.
One housekeeping note. There will be no longer post next weekend. Look out for some shorter Chiplets over the next two weeks though!
GPU Software Ecosystems
We saw in Demystifying GPU Compute Architectures that:
How GPU architectures work is much less widely understood than is the case for CPUs. … Doing things in parallel, though, is inherently more complex and GPUs necessarily expose a lot of complexity.
If GPU compute architectures have a degree of complexity that can make them mysterious, then the software ecosystems that are used to program those architectures are probably even more obscure for many. This post looks to remove a little of that mystery for the general reader.
These software ecosystems are arguably just as important as the GPU hardware itself.
One key takeaway from the earlier post is that it’s not possible to use software designed for CPUs to exploit the potential of modern GPUs, at least without very significant changes or additions. GPU architectures are just too different from their CPU counterparts. So a new set of tools is needed.
This post looks at the major tools in the ecosystem including CUDA, ROCm, OpenCL, SYCL, oneAPI, and others. What are they? Who supports them? What is their history? How do they relate to each other?
These tools will likely be of vital importance in determining who will win in the ongoing ‘AI hardware’ contest. They also provide a fascinating contest between closed and open source and between proprietary and open standards.
It’s worth emphasizing that the effectiveness of these tools is typically highly dependent on support from hardware vendors. With a CPU it’s possible to take details of the instruction set architecture and develop useful tools largely independently of the CPU designer or vendor. We can see this with the importance and quality of third-party open-source compilers such as GNU C/C++ and Clang/LLVM, which work with all the major CPU architectures. This is much less viable (if it’s viable at all) for GPUs, for several reasons:
GPU architectures have been developing and changing more rapidly than is the case for CPUs;
Running code on GPUs almost always needs closed source ‘drivers’ from hardware vendors.
This is not to say that open-source software and open standards don’t have a vital role to play in the GPU software ecosystem. The tools that we will look at often have open-source components or are based on open standards.
This post isn’t a ‘how to get started’ tutorial for aspiring GPU programmers. However, if you are looking to start GPU programming, then it could provide you with a better understanding of the options available when choosing where to start. If you’re looking for programming tutorials then I’ve provided a range of links for these tools at the end of the post.
I also hope that this post is useful for a wider audience. Nvidia’s CUDA is widely seen as being a key part of the ‘moat’ that protects its, now huge, data-center GPU business and supports its multi-trillion dollar market capitalization. Understanding what CUDA is and how it relates to competing software tools must be an important part of any assessment of the strength of CUDA’s moat.
Two relevant points from history.
Several firms recognized the importance of software to support general-purpose computing on GPUs early on. The earliest efforts from AMD, for example, predate the release of Nvidia’s CUDA. Any failings are not due to a lack of awareness of the usefulness of general-purpose computing on GPUs. Perhaps AMD and Intel have struggled to match Nvidia in this area because doing so is hard!
There have been efforts to create common tools and standards, most notably in the form of OpenCL and SYCL. As we’ll see these have had mixed success.
Alongside descriptions of these tools, we’ll provide a short history of their development. I think that it’s useful for readers to understand the trajectory and pace of their development as well as the track record of support provided by their authors.
One note on terminology. I find it difficult to find a single word to describe the tools that we are discussing here. Some are standards coupled with implementations of those standards. Some are often called ‘frameworks’ or ‘platforms’. I’m going to stick with the more generic ‘tools’ for the rest of this post.
Finally, I’ve added some comments alongside each tool on their status and usefulness. These comments are necessarily subjective so please take them as such. This is a complex field with a huge range of applications and a broad range of hardware. Even a long post such as this can only scratch the surface. If you want to know more then I’ve provided lots of suggestions for further reading as we go along and at the end of the post.
Let’s get started with a brief history of programming on GPUs.
A History of GPU Programming

The term Graphics Processing Unit (GPU) was first used by Nvidia in 1999 with the release of the GeForce 256. Nvidia described the GeForce 256 as:
a single-chip processor with integrated transform, lighting, triangle setup/clipping, and rendering engines…
The GeForce 256 brought several functions that had previously typically been performed in software into affordable hardware, providing a major speed-up for many graphics operations in the process.
What do we mean by transform, lighting, triangle setup/clipping, and rendering engines? Without going into detail, these are all stages in the process (or pipeline) of converting a series of 3-D geometric shapes into a 2-D image that can then be displayed on a computer screen.
In the GeForce 256, the operation of each of these stages was fixed in hardware.
Then in 2001, Nvidia introduced the GeForce 3, as the first ‘programmable graphics card’ in which, for the first time, software could be used to influence how some of the stages operated.
Wikipedia provides an example of a graphics pipeline, in which some of the stages are programmable.

Over this period GPUs were being controlled using Application Programming Interfaces (APIs) such as DirectX (from Microsoft) and OpenGL (originally from Silicon Graphics but later an open standard). These allowed the user to write programs on the host computer to control the generation of graphics on GPU hardware.
With the advent of programmable GPUs came the need for software that would run on the GPU itself. One key example of the work that this software needs to do on a GPU is ‘shading’. Wikipedia describes shading as:
a shader is a computer program that calculates the appropriate levels of light, darkness, and color during the rendering of a 3D scene—a process known as shading.
The GeForce 3 had distinct pieces of hardware for different stages in the graphics pipeline. In particular, it had distinct hardware for two types of shading, vertex shading and pixel shading. This approach soon led to some significant problems, as designs became more complex and it became more difficult to balance the hardware needed for different stages of the graphics pipeline.
The solution to these issues came with the next step in the evolution of GPU programming, which again came from Nvidia in 2006. In this significant step, Nvidia removed the distinction between the hardware needed for different stages of the pipeline and replaced it all with a single new processor architecture.
We pretty much threw out the entire shader architecture from NV30/NV40 and made a new one from scratch with a new general processor architecture (SIMT), that also introduced new processor design methodologies. - Jonah Alben (Interview with extremetech.com. SIMT is Single Instruction Multiple Thread).
This change was introduced in the Nvidia G80 GPU. This approach, with multiple ‘Streaming Multiprocessors’ performing a variety of distinct tasks has evolved over the last decade and a half into the approach that we described in Demystifying GPU Compute Architectures.
Crucially this change opened up the range of possibilities for general-purpose programming on GPUs. Instead of having multiple programmable stages that were focused on one type of operation and so had distinct instruction sets that were focused on those operations, the G80 changed to use a single, more general-purpose, architecture.
Nvidia spotted this opportunity and introduced tools to support general-purpose programming on GPUs, which it called CUDA, for Compute Unified Device Architecture, in June 2007. We’ll discuss the development of CUDA in more detail later.
GPU Software - What and Where?
Before we look at CUDA and the other major software tools for general-purpose programming on GPUs we need to clarify what that software does.
With software running on a CPU, we can normally break it down into several hierarchical layers. For a program written in a compiled language such as C or C++, we might have (in a highly simplified presentation)
The programmer writes program code in a programming language that utilizes code from one or more frameworks or libraries. This is then compiled into machine code for the relevant CPU architecture adopted by the machine. That machine code will use capabilities provided by the machine's operating system to perform common tasks such as reading or writing from storage.
When we talk about programming a GPU we can use this model but there is an extra dimension to add to this picture. We need to consider where will any code run, either on the CPU or the GPU.

CUDA processing flow - By Tosaka - Own work, CC BY 3.0, https://commons.wikimedia.org/w/index.php?curid=5140417
We can recall from the earlier post that GPUs are controlled by a CPU. The CPU determines what programs the GPU runs and how it runs them, and controls the transfer of data to and from the GPU. The GPU has no capabilities to communicate with disks and other input and output devices so this needs to be handled by the CPU. So when we talk about GPU programming tools a large component of any set of tools inevitably runs on the associated CPU.
Going back to our model, the compiler that generates machine code from program code runs on the CPU. However, it needs to generate machine code that runs on both the CPU and the GPU. The CPU code has two roles. It interacts with the rest of the system and, crucially, controls much of the operation of the GPU. The GPU machine code is the code that runs on the streaming multiprocessors that we discussed earlier.
So any set of tools for general-purpose programming on GPUs potentially has several distinct but important components:
A programming language (typically C or C++) for the user to use to implement their programs running on the CPU;
A language to specify programs (kernels) that run on the GPU’s streaming multiprocessors (SMs);
A compiler to turn kernels into machine code running on the GPU’s SMs;
Code that runs on the CPU that controls key aspects of the operation of the GPU including:
Transferring compiled kernel code to the GPU;
Specifying how the GPU runs which kernels and when;
Transferring data between the CPU and the GPU;
Libraries that give user code on the CPU access to this code to control the GPU;
Libraries, for either CPU or kernel code for the GPU, to perform other common tasks. This pre-written code might provide highly optimized implementations of tasks where performance is critical.
Each of these components has an important role to play in ensuring that users can readily create performant software running on the GPU.
Not to forget that the usability of any software depends in part on the quality of the ecosystem around it. On the quality of debugging tools, profilers, and so on.
Before we move on it may be useful to provide a checklist that can act as a starting point in the evaluation of any set of tools for general-purpose GPU programming:
What hardware does the tool run on?
Which manufacturers, models, and hardware generations?
What is the record of support for the tool?
How long has it been supported?
How frequently is it updated and how recent is the last update?
How good is the support and the documentation?
This might include manuals, forums, user groups, and so on.
How extensive, performant, and useful are the frameworks/libraries that are associated with it?
How performant is it?
Is there a track record of updates that improve performance?
It will be no surprise that the first tool on our list, Nvidia’s CUDA, performs well on all of these measures apart from the very first. CUDA is Nvidia only, although there have been attempts by other manufacturers to achieve a degree of compatibility, as we’ll see with AMD’s ROCm.
A brief word about the frameworks that are commonly used for machine learning training and inference, such as PyTorch from Meta and Tensorflow from Google. At first sight, these don’t seem to fit into the model we have described above. For both the user writes code in Python, an interpreted language, rather than in a language that is compiled to machine code running on the CPU or GPU. The heavy lifting for these frameworks (and similar tools) is done by code written in a compiled language like C or C++ and, if it runs on a GPU, will utilize one of the tools that we’ll discuss here (such as and most commonly CUDA) and include GPU-specific kernels. The Python code provides a convenient way for users to access that compiled code for a range of predetermined tasks related to deep learning.
Even in a post as long as this we won’t have space to examine how PyTorch and Tensorflow utilise CUDA and other tools. For a look in detail at this Dylan Patel’s post from last year is a great starting point:

Before looking at each of the tools it’s worth thinking about them as (possibly part of) an answer to a range of questions. The answer will vary depending on the question. So questions such as, what to use to:
Get the best performance on a range of machine learning tasks within a given hardware budget?
Deploy GPU acceleration across as wide a range of hardware platforms as possible?
Could have very different answers.
If we want to compare the adoption of the tools we’ll discuss then this slide from 2020 from Simon McIntosh-Smith is interesting. It shows the popularity of CUDA and a recent uptick (due to increasing interest in machine learning?). Being based on mentions in research papers, it’s biased towards research rather than commercial deployment but still gives an interesting insight into some crucial comparisons (CUDA vs OpenCL for example). Note that we won’t discuss MPI, Cilk, or TBB further as they aren’t directly comparable with the other tools mentioned here.
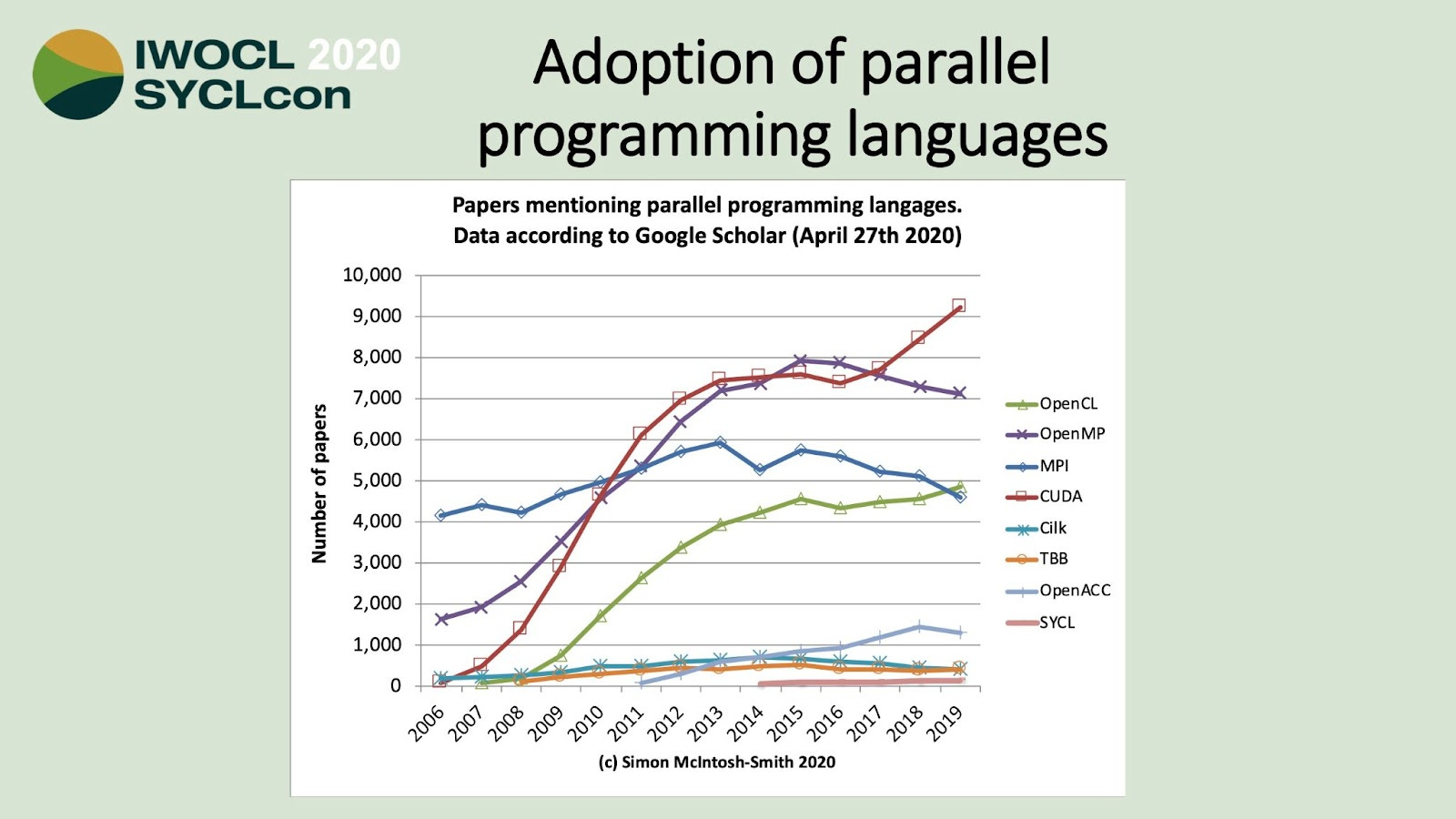
Source https://www.iwocl.org/wp-content/uploads/iwocl-syclcon-2020-panel-slides.pdf
We can now look at each of the major tools, starting with CUDA. We’ll end with an explanation of some other parts of the ecosystem and how they fit in with the tools that we’ve discussed.
The rest of this post - the majority - is for premium subscribers. In it, we look at Nvidia’s CUDA, OpenCL, AMD’s ROCm, SYCL, OneAPI, Vulkan, Metal, and more. How do the contenders for CUDA’s crown compare?
If you’re not a premium subscriber you can join using the button below.
