


Nvidia's PTX
Some background to the 'virtual instruction set' that underpins CUDA

We discussed the history of Nvidia’s CUDA in Happy 18th Birthday CUDA!
Let’s recap how Wikipedia defines CUDA. It’s:
… a software layer that gives direct access to the GPU's virtual instruction set and parallel computational elements for the execution of compute kernels. In addition to drivers and runtime kernels, the CUDA platform includes compilers, libraries and developer tools to help programmers accelerate their applications.
So CUDA sits on top of, what Wikipedia calls, the GPU’s virtual instruction set.
Nvidia call this virtual instruction set PTX for Parallel Thread eXecution. PTX has been in the news because DeepSeek highlighted their use of PTX in their technical report on their R3 Large Language Model.
Here’s Ben Thompson of Stratechery commenting on DeepSeek’s use of PTX:
Here’s the thing: a huge number of the innovations I explained above are about overcoming the lack of memory bandwidth implied in using H800s instead of H100s. Moreover, if you actually did the math on the previous question, you would realize that DeepSeek actually had an excess of computing; that’s because DeepSeek actually programmed 20 of the 132 processing units on each H800 specifically to manage cross-chip communications. This is actually impossible to do in CUDA. DeepSeek engineers had to drop down to PTX, a low-level instruction set for Nvidia GPUs that is basically like assembly language. This is an insane level of optimization that only makes sense if you are using H800s.
So Ben calls use of PTX an ‘insane level of optimization’ that does things that are ‘impossible to do in CUDA’.
So what’s PTX all about and just what is a ‘virtual instruction set’? And, perhaps, most intriguingly, why has Nvidia decided to use PTX rather than a real instruction set? In this post we’ll set out to understand why.
The Origins of Virtual Instruction Sets
The earliest programs on modern computers were written first in machine code and then in what we now call assembly language. Use of these ‘low level' languages was both inefficient and error prone, so soon led to the development of ‘high level’ languages which a compiler converted to machine code.
This also enabled a greater level of portability between machines. In theory code written in Fortran, for example, would then run on computers from IBM, Univac, GE or a number of other firms.
However, even this wasn’t ideal. In the 1950s new languages and computer architectures proliferated. Every time a new architecture or high-level language was developed then a number of new or revised compilers were needed. For every new language, compilers for each architecture were needed and for a new architecture compilers for each language were necessary.
This led to what became known as the ‘n * m problem’. With n architectures and m machines, n * m compilers were needed to implement all the languages on all the architectures. Writing a new compiler was a significant undertaking.
Users wanted a better approach.
SHARE was a user group for IBM mainframe computers, founded in Los Angeles in 1955 by users of the IBM 704 mainframe. SHARE soon became a popular way for mainframe users to exchange technical information and software. Incidentally, SHARE is now seen as one of the key inspirations for the ‘Free Software’ and ‘Open Source’ software movements.
In August 1958 a small group of SHARE members submitted a paper titled The Problem of Programming Communication with Varying Machines to the Association for Computing Machinery. The paper starts with a clear statement of the problem:
One of the fundamental problems facing the computer profession today is the considerable length of time required to develop an effective method of communication with the machine. Moreover, it seems that the ability to communicate easily is no sooner acquired than the language changes, and the problem is renewed, usually at a higher level of complexity.
To give some idea of how early this was, the first correct running of a FORTRAN program only took place in 1958, although the language had been specified in 1956.
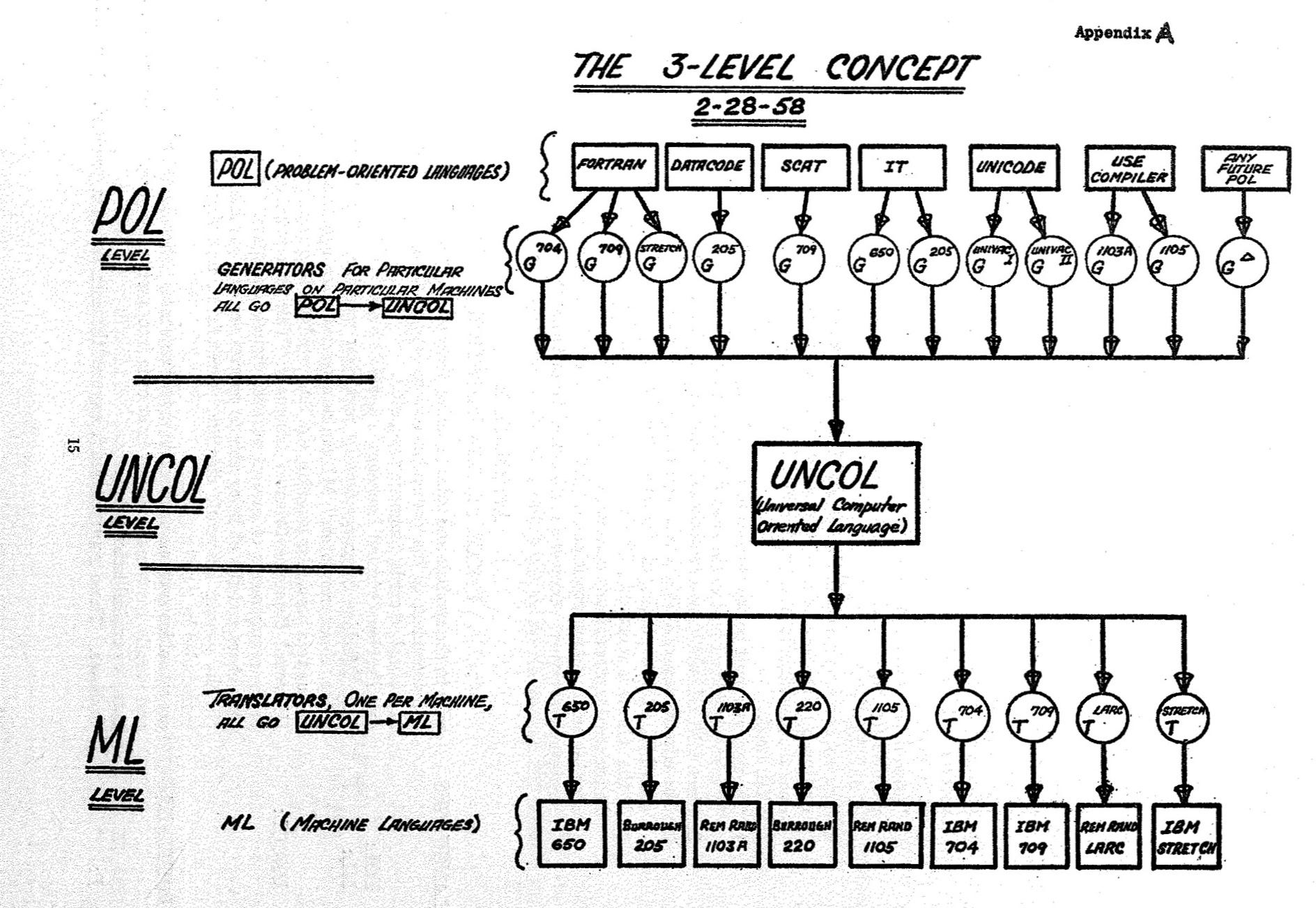
The paper didn’t just set out the problem, it proposed a solutiion: what it called ‘THE 3-LEVEL CONCEPT’
Much of the terminology in the paper is archaic: ‘POL’ (for Problem-Oriented Language) was used instead of the modern ‘High-Level Languages’. The paper proposed that code written in a ‘POL’ such as FORTRAN would be first compiled to what it called a ‘Universal Computer Oriented Language’ or ‘UNCOL’.
This UNCOL would pass through a ‘translator’ that would convert it to ‘Machine Language’ for the required computer architecture. The paper mentioned the architectures for IBM machines including the IBM 650, IBM Stretch, IBM 794 and machines from Remington Rand and Burroughs.
So instead of n * m compilers full implementation of n languages for m architectures would need n compilers to UNCOL plus m translators to machine language - plus the extra work of creating and maintaining the UNCOL.
The SHARE paper articulated the idea of UNCOL, but it didn’t propose an implementation.
It wouldn't be long, though, before someone did. A few months later a letter and accompanying paper appeared in Communications of the ACM, both written by Melvin Conway. The paper was titled Proposal for an UNCOL and the letter stated that:
… I have developed an UNCOL, a version of which we will use when we put the RUNCIBLE successor on the Univac. The enclosed paper describes the language in the jargon of the August report.
The paper described Conway’s ‘SML’ - for ‘Simple Machine Language’ - as his proposed UNCOL.
‘SML’ turned out to be an impractical proposal but was the first of many projects to develop an UNCOL over the following decades. In fact UNCOLs - or as we now call them ‘Intermediate Representations (IRs)’ or ‘virtual instruction sets’ corresponding to ‘virtual machines’ - have become ubiquitous.
Some notable examples include:
o-code (1966) - for the BCPL language.
UCSD p-code (1973) - for the UCSD p-System and UCSD Pascal:
UCSD Pascal is a Pascal programming language system that runs on the UCSD p-System, a portable, highly machine-independent operating system. UCSD Pascal was first released in 1977. It was developed at the University of California, San Diego (UCSD).
JVM (1994):
A Java virtual machine (JVM) is a virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode.
MSIL (for Microsoft Intermediate Language) which would later become standardised as the CIL (Common Intermediate Language)
LLVM IR (2003) for the LLVM compiler system:
LLVM often also refers to just the optimizer and backend parts of Clang; this is can be thought of as a compiler for the “LLVM language” or “LLVM assembly”. Clang, and other language frontends like Rust, essentially compile to LLVM IR, which LLVM then compiles to machine code. Source
WASM (2017)
WebAssembly (Wasm) defines a portable binary-code format and a corresponding text format for executable programs as well as software interfaces for facilitating communication between such programs and their host environment.
As is the case for high-level languages these UNCOLs can be interpreted (p-code, JVM, CIL, WASM) or compiled (o-code, LLVM IR).
In each of these cases there may be other reasons for using a virtual instruction set but avoiding the full impact of the ‘n * m’ problem is often part of the rationale. For example for Java and the JVM it was part of Sun’s marketing and led to a famous slogan:
Write once, run anywhere (WORA), or sometimes Write once, run everywhere (WORE), was a 1995 slogan created by Sun Microsystems to illustrate the cross-platform benefits of the Java programming language. Ideally, this meant that a Java program could be developed on any device, compiled into standard bytecode, and be expected to run on any device equipped with a Java virtual machine (JVM). The installation of a JVM or Java interpreter on chips, devices, or software packages became an industry standard practice.
Binary Compatibility as a Hardware Strategy
Which brings us to Nvidia and PTX.
Nvidia released the first version of CUDA in 2007. From that very first release the compilation process for CUDA ‘c-like’ code involved compilation to PTX as an intermediate step.
Surely this was an overhead for Nvidia though? Nvidia doesn’t need to face the ‘n * m’ problem as it had a small number of high level languages to deal with and full control over its own architecture. Why would Nvidia take this approach?
First, lets make an observation about the intermediate languages we listed above: they have typically been developed by language designers or compiler writers who want to allow their language(s) to ‘run everywhere’.
Hardware designers and makers have typically taken a different approach though.
If we go back to the 1960s when UNCOL and it’s immediate successors were being developed, IBM (partially) solved the ‘n * m’ problem for its System/360 and later mainframe architectures by offering:
First
A range of machines of varying performance at different price points;
All of which executed the same machine code;
… and then by
Releasing later more powerful machines that were fully backwards ‘machine code’ compatible.
This made use of an UNCOL or ‘Intermediate Representation’ unnecessary.
It also made it harder for competitors to create computers that could run software designed for IBM’s mainframes. Those machines would need to be fully ‘binary compatible’ rather than simply using a translator to translate the Intermediate Representation to an incompatible machine code.
What was true for IBM in the mainframe era became true for Intel in the microcomputer era. As the dominant maker of microprocessors, starting in 1976 and continuing to the present day, Intel has created successive x86 architecture designs that again offered varying performance at a range of price points and were fully backwards compatible with the previous generation machines.
Intel had a more difficult job in transitioning x86 from an 8/16 bit architecture (the 8086 in 1976) with 1 MB of address space to a fully 64-bit one (today).
But Intel had a key ally in this challenge: Moore’s Law. The exponential growth of the number of transistors made it easier to recreate ‘legacy’ features of the architecture without affecting cost or performance so as to make x86 uncompetitive.
Most recently though this approach has started to break down. Features of the ISA such as AVX512 have not been consistently implemented across Intel’s designs and new designs have not always been fully backwards compatible.
Intel is even proposing stripping out some of the decades of cruft that have been accumulated in the x86 ISA with its 2023 APX proposals.
Intel APX

Intel has just announced APX, “the next major step in the evolution of Intel® architecture”:
PTX in Nvidia’s Strategy
Nvidia took a different approach with PTX. The rationale(s) succinctly set out by Nvidia are (with my emphasis):
Provide a stable ISA that spans multiple GPU generations.
Achieve performance in compiled applications comparable to native GPU performance.
Provide a machine-independent ISA for C/C++ and other compilers to target.
Provide a code distribution ISA for application and middleware developers.
Provide a common source-level ISA for optimizing code generators and translators, which map PTX to specific target machines.
Facilitate hand-coding of libraries, performance kernels, and architecture tests.
Provide a scalable programming model that spans GPU sizes from a single unit to many parallel units.
There are some interesting perspectives that inform Nvidia’s decision to use PTX which each relate back to key aspects of the company’s strategy.
CUDA runs everywhere
Nvidia wanted to get CUDA into as many developers’ hands as possible. A scalable programming model that spans GPU sizes allowed them to offer CUDA compatible cards at a full range of price points.

Nvidia as a software company
Nvidia itself produces a lot of software. By some estimates, half of Nvidia’s engineers are software engineers. A stable ISA avoids duplication of effort for those software engineers across multiple classes and generations of GPU.
PTX allows Nvidia’s architectures evolve
A machine-independent ISA allows Nvidia’s architectures to change significantly over time without breaking compatibility. There have been numerous breaking architecture changes in the 18 years since CUDA was launched. Just one example, the instruction size is 16 bytes on Volta and later architectures, and 8 bytes on prior architectures.
And this final point brings us back to the ‘n * m’ problem. Nvidia could have avoided the problem by ensuring backwards compatibility at the architecture level. That would have been at the cost of not allowing breaking changes to the architecture with the potential performance penalties that this might imply. Instead Nvidia gave itself the ability to deal with an ‘n * m’ problem and so gave itself the ability to evolve its architecture.
The Costs of PTX
But this was not cost-free: PTX comes with it’s own overheads.
The CUDA 18th birthday post attracted an interesting comment from a former Nvidia engineer:
CUDA was this “annoyance” we had to deal with … Gfx made all the money yet CUDA was treated as first class citizen since the day it was born.
PTX was part of the CUDA infrastructure right from CUDA 1.0.
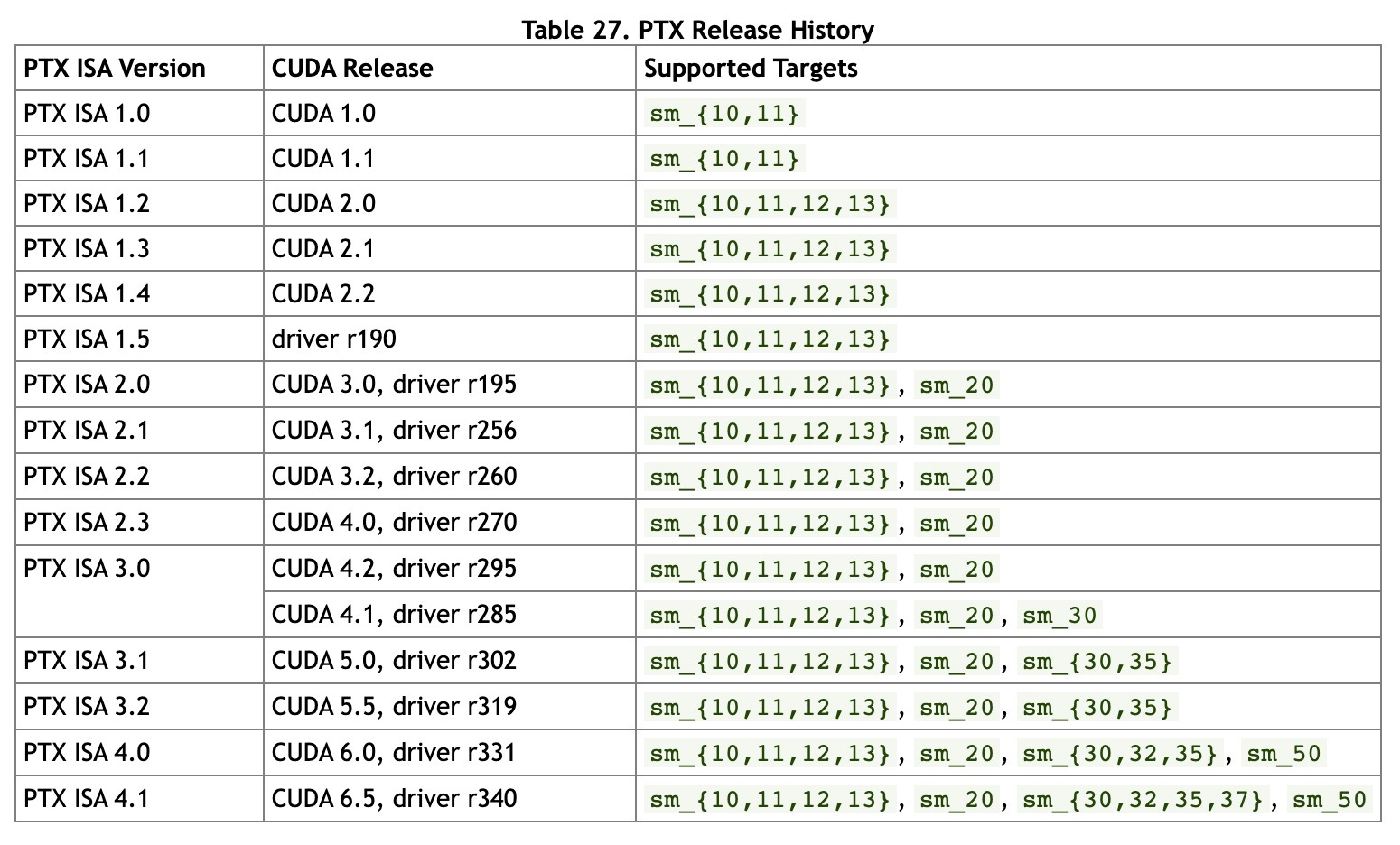
If at first CUDA as a whole was an annoyance then I’m sure that including PTX didn’t help. It would certainly have been quicker and cheaper for Nvidia to initially release CUDA with tools that directly targeted the underlying GPU instruction sets.
The firm had to develop PTX in addition to the ISA for the underlying GPU and to do so with sufficient care to ensure that it would be able to continue to continue to use PTX in future generations of GPU hardware.
PTX is not a trivial standard to support. Today, the documentation for the PTX ISA runs to around 600 (fairly terse) pages.
Nvidia accepted these (ongoing) costs in the interests of supporting its longer term strategy.
PTX in Practice
Nvidia has just published a blog post Understanding PTX, the Assembly Language of CUDA GPU Computing with a good introduction to the role that PTX plays.
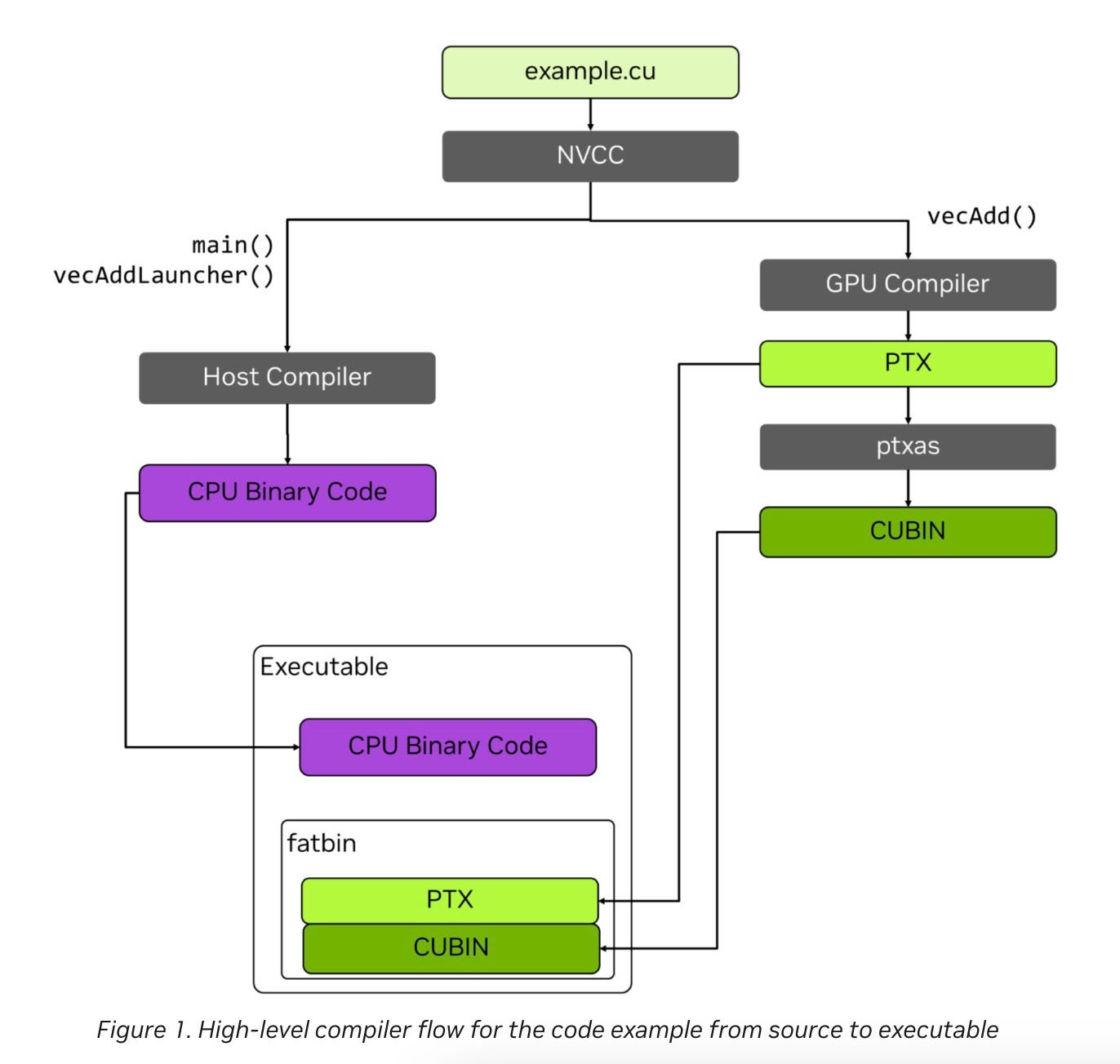
To summarise, very briefly, a CUDA program compiled with Nvidia’s NVCC compiler results in (1) code that runs on the CPU and (2) PTX code as well as (3) machine code for a specific GPU.
Nvidia explains why this is useful (my emphasis):
Importantly, this compilation of PTX for a specific GPU can happen just-in-time (JIT) at application runtime. As shown in Figure 1, the executable for an application can embed both GPU binaries (cubins) and PTX code. Embedding the PTX in the executable enables CUDA to JIT compile the PTX to the appropriate cubin at application runtime. The JIT compiler for PTX is part of the NVIDIA GPU driver.
Embedding PTX in the application enables running the first stage of compilation—high-level language to PTX—when the application is compiled. The second stage of compilation—PTX to cubin—can be delayed until application runtime. … doing this allows the application to run on a wider range of GPUs, including GPUs released well after the application was built.
PTX and SASS
Just to complete our brief introduction to PTX, there is one final question to answer. If PTX is an intermediate lang then what is (or more properly are, as there are several) the real assembly language for Nvidia GPUs?
Nvidia intentionally does not provide detailed documentation for those assembly languages.
It does, however, support disassembly to what is known as ‘SASS’ (for Streaming ASSsembler) and provides some limited information. For example the assembly mnemonics for its recent architectures are listed here as part of the documentation for its nvdisasm utility.
We’ll look in more detail at PTX and its uses in the next post in this series.
Note that IBMs and Intel's use of S/360 and x86 machine code as an UNCOL are very different to each other.
IBM announced a range of machines at varying price and performance points on day #1. High end machines used all or mostly direct hardware implementation, low end machines used long sequences of narrow microcode to implement each instruction, with sometimes an 8 bit datapath/ALU -- they could have done bit-serial but I don't think ever did on 360. Machines in the middle used shorter sequences of wide microcode. Later they introduced entire new ranges of machines using newer technology and expanded instruction sets, and every machine from the top to the bottom ran exactly the same programs (RAM size permitting). They may even have retrofitted new microcode to old machines ... I don't know if they did.
DEC, DG, Pr1me and others followed similar strategies.
In contrast, with maybe only Atom and E cores in the newest chips as exceptions, Intel has only ever introduced better and faster CPU cores with expanded instruction sets, At a given time they introduce a range of CPUs varying in clock speeds on the same chips (by testing, or artificially), varying amounts of cache, and since 2010 or so with a varying number of CPU cores physically present or enabled. Previous generation CPUs may continue to be sold at a discount, but they will have worse IPC and energy consumption and don't have the most recent instructions.