
The Unnecessary Obscurity of Assembly Language
We still sometimes need to read assembly language. Why do we make it so hard?

Over Easter I’ll be sharing some shorter posts rather than a longer read on Sunday. This first post looks at the readability of assembly language.
Even in 2023, if we want to make the most of our hardware, then it’s still sometimes necessary to dip into assembly language. The most recent work on getting machine learning applications running on desktop PCs (for example the amazing port of OpenAI’s Whisper to C++ by Georgi Gerganov) have made extensive use of vector instructions and I’m sure debugging these has involved some reading of assembly language output. But reading assembly is really quite hard. Does it need to be so?
The recent article ‘Only Wizards Used Assembly Language’ by
at Goto 10 RetroComputing: Atari and more got me thinking about the role that assembly languages have played over the years.Wikipedia describes assembly language as:
any low-level programming language with a very strong correspondence between the instructions in the language and the architecture's machine code instructions.
Paul describes how he regarded assembly language as being for ‘Wizards’ in the 1980s. It’s certainly true that most people just used BASIC to program their home computers. I think, though, that there was probably a lot more assembly language programming going on in general than is the case today. Today we have high quality C / C++ / Rust compilers, which would be used where assembly would have been used in the era of 8-bit systems.
To try to test out my hypothesis here is a poll to see how the ‘Chip Letter’ readership splits on this issue. Please vote for an assembly language even if you've used (or read it) a little, at any time in the past.
There is no doubt that it’s really hard to build software in assembly. Building complex programs things out of small, simple building blocks is undoubtedly much more challenging than using higher level abstractions.
But even if we don’t often need to write assembly these days, it’s sometimes the case that we need to read it. The popularity of the website Compiler Explorer, which shows the assembly language generated by your program in C / C++ (or lots of other languages), indicates that there is often a real need to understand what your high level program is doing at the assembly language level.
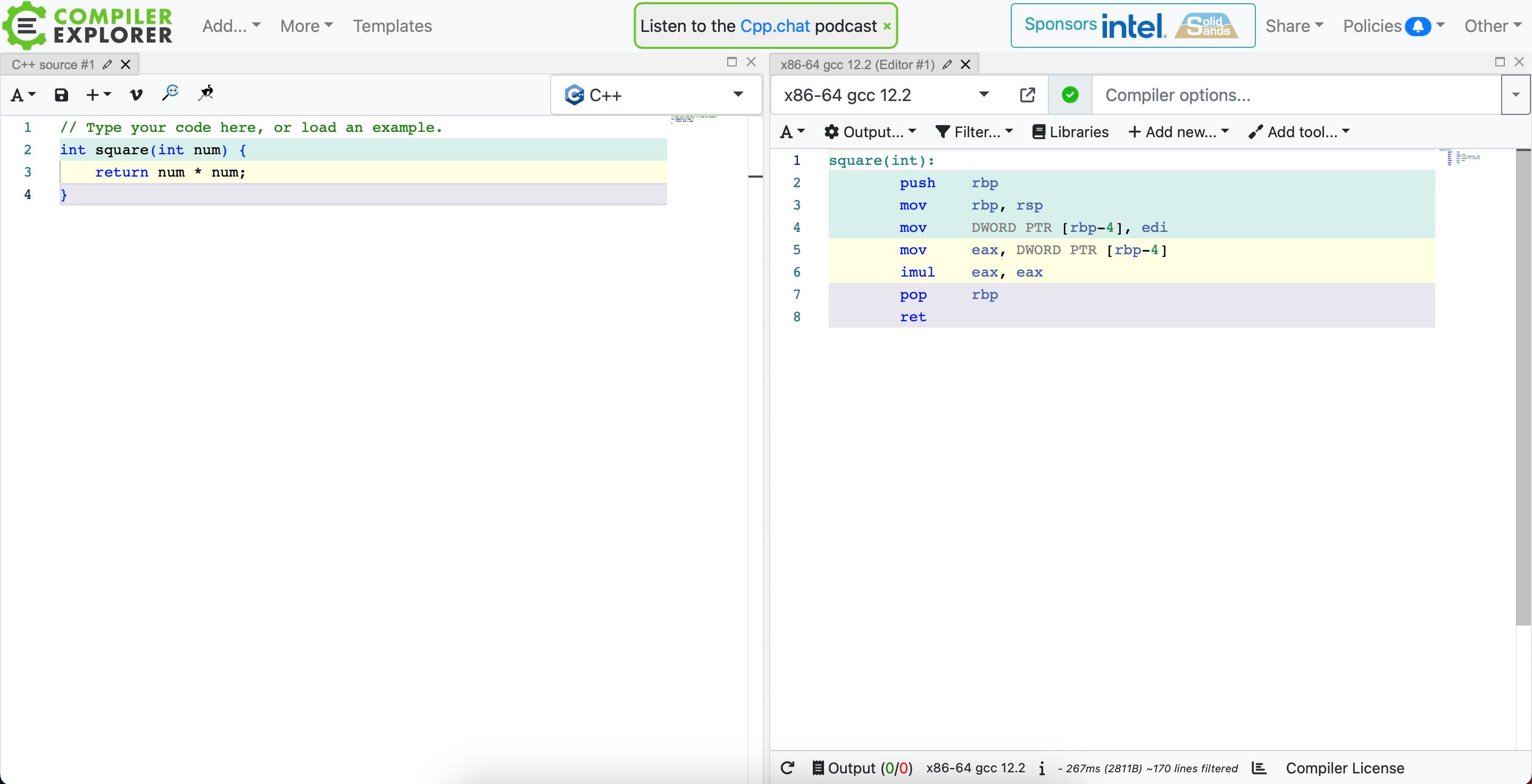
I’ve used Compiler Explorer myself when using Intel’s AVX512 vector instructions.
Given this, assembly language is really hard to read. Here is some sample output from Compiler Explorer. My eyes have usually glazed over by the third ‘movq’.

Let’s just take a simple operation like copying from one register to another. x86, Intel format, has:
mov ebx, eaxThe use of a three letter abbreviation (TLA) may have made sense when a few KB on file sizes was a key issue, but maybe not in 2023?
Then of course there is AT&T syntax which reverses the order of the registers and adds a couple of unnecessary ‘%’s.
mov %eax, %ebxAnd let’s not get into constructions like:
mov (%esi,%ebx,4), %edxWhen we get into more complex instructions then the naming gets even more confusing. 64-bit Arm has the infamous Seven Letter Abbreviation:
FJCVTZS W0, D0or ‘Floating-point Javascript Convert to Signed fixed-point, rounding toward Zero.’ I’m not criticising the need for this instruction, but does ‘FJCVTZS’ really tell you what this instruction is doing?
Intel’s AVX512 has lots and lots of examples like this (eg ‘VCVTTPD2UDQ’ with an Eleven Letter Abbreviation!) and lots and lots of them look really similar.
I could go on, but I’m sure the message is clear: assembly language is really hard to read for the occasional reader. Does it need to be so?
In the earliest days of computing, before the invention of high level languages, assembly language was the only way that you could program the computer.
The first use of what we would today call assembly language appears in the paper ‘Coding for A.R.C’ by Andrew Booth and Kathleen Britten, written as early as 1947 (although a version of the notation appears in an earlier paper). The paper and the background to it are really interesting in many ways, but for this post I’d like to focus on the form of the assembly language it uses. Here is one example:

So taking the simplest example, the assembly language to copy A to R is just ‘A to R’.
This seems a lot more sensible to me than ‘MOV %R, %A’. Booth and Britten actually wanted their assembly language to be readable!
It really feels to me like assembly language took a wrong turn at some point. For a language that is mostly read rather than written, then it’s really not readable at all. Even the first ever assembly language was more readable than the ones we use today.
Can and should we have made assembly language more readable? We don’t write our high level languages in Three Letter Abbreviations or Seven Letter Abbreviations or even Eleven Letter Abbreviations, so why do we still do so for Assembly Language? Why has there been no attempt to get some consistency between architectures? Do let me know what you think in the comments.
I wished at least assembler syntax would at be standardized for the x86 ISA so that we don't have AT&T vs Intel syntax as well as slightly different mnemonics across various assemblers/compilers. As far as the instruction names, maybe in addition to standardized short form mnemonics, the standard could also define longer descriptive aliases for the same opcode, and/or maybe allow the user to define their own alias in the asm source.
Having a standard where the machine code would also optionally retain labels would be helpful too in debugging / disassembly. Or does that exist? I suppose it verges into compiler symbols maybe such asm labels could be stored in the same section. In working with Solaris in the past, one the most brilliant features the engineers implemented in the OS, compiler and debugger was always pushing the arguments for each function call onto the stack even if the arguments were actually passed by registers. The debugger, mdb or kmdb would retrieve this information for each stack frame and display it as arguments. It results in extra overhead but an intentional and worthy compromise IMHO, invaluable for debugging and troubleshooting. It worked for live disassembly with their debugger as well as with core dumps to retain the current arguments for the whole stack trace.
One could argue the best way to "read assembly" is to read it's LLVM IR code.
The IR is why nearly all compiler development efforts have been switched to LLVM in recent years, and for good reason.
For one, it's actually a language meant to be read. Still, while staying implementation agnostic, it very closely resembles your machine code implementation.
And even if you don't have a source code, there are "lifters"" which translate your assembly code into IR, which in turn you can always compile back.