
SOAR-ing with Smalltalk: Berkeley RISC-III
'Smalltalk On A RISC' and three mysteries!

The simplicity of the Berkeley RISC designs provided a powerful platform for innovation. It’s a superpower that continues today with RISC-V.
In today’s post, we look at an architecture designed at UC Berkeley soon after the first Berkeley RISC designs.
At the time it was called SOAR, for ‘Smalltalk ON A RISC’, but has retrospectively also become known as RISC-III.

Before we look at SOAR a quick recap on RISC at Berkeley.
Berkeley RISC
Reduced Instruction Set Computer (RISC) Architectures from the University of California Berkeley have been hugely influential. Berkeley RISC-I was the first VLSI implementation of a RISC design and the RISC acronym itself was invented at Berkeley.
We discussed Berkeley RISC-I (from 1980/1) and RISC-II (from 1981/2) in RISC on a Chip: David Patterson and Berkeley RISC-I:

More recently, the increasingly important RISC-V Instruction Set Architecture was first developed at the Parallel Computing Lab at Berkeley.
We discussed RISC-V in RISC-V - Part 1: Origins and Architecture and then in RISC-V - Part 2: Ambitious Aims.

But what about RISC-III and RISC-IV?
In this post we’ll look at RISC-III, or as it was known at the time, SOAR, which is less well-known than other Berkeley designs but, in many ways just as interesting. We’ll complete the ‘Berkeley RISC set’ with RISC-IV or SPUR in a future post.
Smalltalk and Object Oriented Programming
Before we can talk about RISC-III we need to discuss the Smalltalk programming language. Smalltalk was getting a lot of attention in the 1970s and early 1980s and has proven to be highly influential in the development of many modern programming languages. Today Python, Ruby, Java, Objective-C, and many other languages can all trace key features back to Smalltalk.
At the heart of Smalltalk is the idea of object-oriented programming. The object-oriented concept first appeared in the Simula programming language in 1962. Further research on object-oriented programming was undertaken 1at Xerox PARC leading to the appearance of the Smalltalk language in 1972. Work on Smalltalk continued in the 1970s culminating in the Smalltalk-80 version of the language.
By 1981 interest in Smalltalk was widespread enough for Byte magazine to feature it in a special edition.

The editorial Smalltalk: A Language for the 1980s in this edition concluded that ‘I came away enthused by this revolutionary language.’ And indeed Smalltalk had revolutionary promise. At the core of that promise was that powerful software systems could be developed more quickly than with other languages.
Evidence for the benefits of this approach was clear from the systems showcasing Smalltalk that had been developed at Xerox PARC, most notably the Xerox Alto. The Alto ...
is considered one of the first workstations or personal computers, and its development pioneered many aspects of modern computing. It features a graphical user interface (GUI), a mouse, Ethernet networking, and the ability to run multiple applications simultaneously.
The Computer History Museum has a great video of Smalltalk pioneer Dan Ingalls using Smalltalk on an Alto.

Steve Jobs would later mention object-oriented programming as one of the things that he had missed on his famous tour of Xerox PARC. That miss would later be rectified as the Objective-C language, with its strong Smalltalk influence, would become a key part of the software stack for Jobs’s Next Computers. That software stack would in turn help underpin Mac OS and then iOS when Jobs returned to Apple.
In short, in the early 1980s, Smalltalk was a big deal!
Speeding Up Object-Oriented Languages
However, most Smalltalk-80 implementations had a major problem: they typically ran programs very slowly. Why was this? Several factors slowed down the execution of Smalltalk-80 programs, including:
Bytecode: Smalltalk-80 programs are compiled down to a ‘bytecode’ format and then executed using a virtual machine. This adds a layer of overhead as each bytecode needs to be ‘decoded’ to decide what it means before actually performing the instruction that it implies.
Dynamic Typing and Polymorphism: Smalltalk-80 variables are dynamically typed and the language is polymorphic. This means that 1) the nature of the variable - integer, floating point, string, and so on - is not specified by the user in advance, and 2) even simple operations such as ‘+’ can apply in different ways to different variable types. This means that Smalltalk-80 potentially needs to check for variable types while performing common operations such as ‘+’ to ensure the correct operation is performed.
Subroutine Calls: Smalltalk-80 programs make many subroutine calls, which potentially incur the significant overhead of saving and then re-loading registers on a register-based machine.
Object Management: Almost everything in Smalltalk-80 is an ‘object’, even integers. Smalltalk-80 programs typically create and then destroy very many ‘objects’ in memory, with the associated memory management overheads.
These issues led to attempts to create hardware that would be fast enough to properly showcase Smalltalk’s capabilities. Most notably Xerox created the Xerox Dorado, a descendant of the Alto, in 1978 which was built using fast - but very expensive - ECL chips and with microcode created specially to support Smalltalk.
The Dorado set the ‘gold standard’ for Smalltalk systems at the time. However, an expensive machine would not help Smalltalk gain wider adoption. So researchers started looking for cheaper approaches.
Berkeley Smalltalk
Smalltalk research at UC Berkeley started with an implementation of Smalltalk-80 known as Berkeley Smalltalk (or BS). BS was written in C and ran on a DEC VAX 11-780 minicomputer under Berkeley’s own Unix implementation.
Smalltalk performance was the central focus of this research and led to the 1982 paper Berkeley Smalltalk: Who Knows Where the Time Goes? by David Ungar and David Patterson. It concluded:
Other Smalltalk-80 implementations on non-microprogrammable computers have suffered from poor performance. We believe that a straightforward, literal implementation of the specification cannot achieve acceptable performance. This paper explains how the optimizations in BS have increased performance fourfold.
The results from the Berkeley Smalltalk project were promising. The BS Compiler delivered speed-ups of between 3.7 and 12 times for common tasks undertaken by the Smalltalk system:
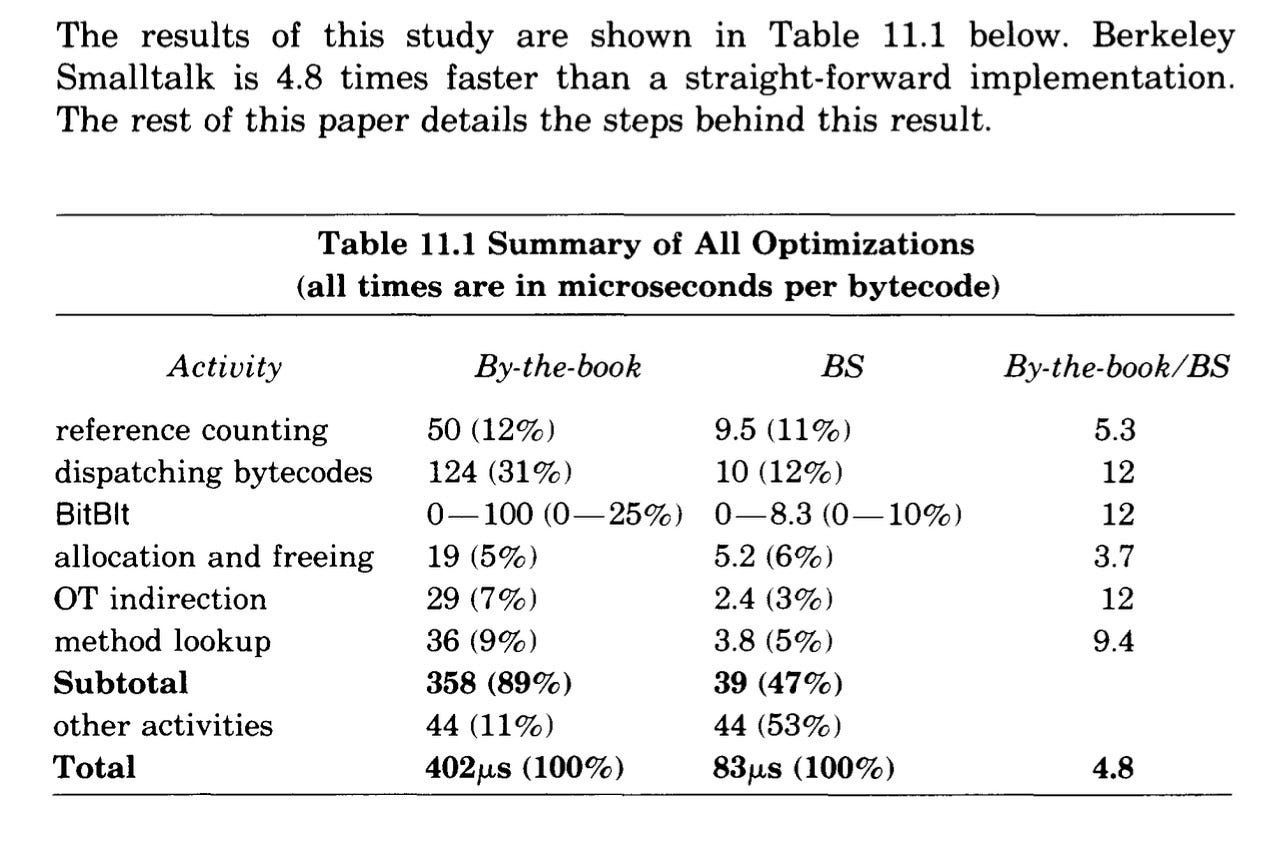
The project also provided key insights into Smalltalk-80's performance. These results would then inform the development of the next Smalltalk Research project at Berkeley, one that would look at specialized hardware.
Smalltalk On A RISC
The Berkeley RISC-I and RISC-II projects had shown that RISC designs could deliver significant performance gains. If Smalltalk and object-oriented programming were the future then perhaps a RISC architecture specially adapted for the Smalltalk language might help answer Smalltalk’s performance issues.
So the ‘Smalltalk On A RISC’ or ‘SOAR’ project at UC Berkeley was born as an undergraduate project under the supervision of David Patterson and David Hodge2.
Before we look at SOAR in more detail, regular readers may recall another architecture, whose development had started a few years earlier, that aimed to accelerate the execution of a high-level language (in this case Ada): Intel’s iAPX432.
As we saw in iAPX432 : Gordon Moore, Risk and Intel’s Super-CISC failure. That project did not lead to a commercially successful architecture.
Six years in development, it was repeatedly delayed and when it was finally launched it was too slow and hardly sold at all. It was officially cancelled in 19861, just five years after it first went on sale.
SOAR Basics
The Berkeley SOAR design would be very different from the iAPX432. As might be expected from Berkeley it was a RISC design that built on, and had much in common with, the earlier RISC-I and RISC-II designs.
Registers
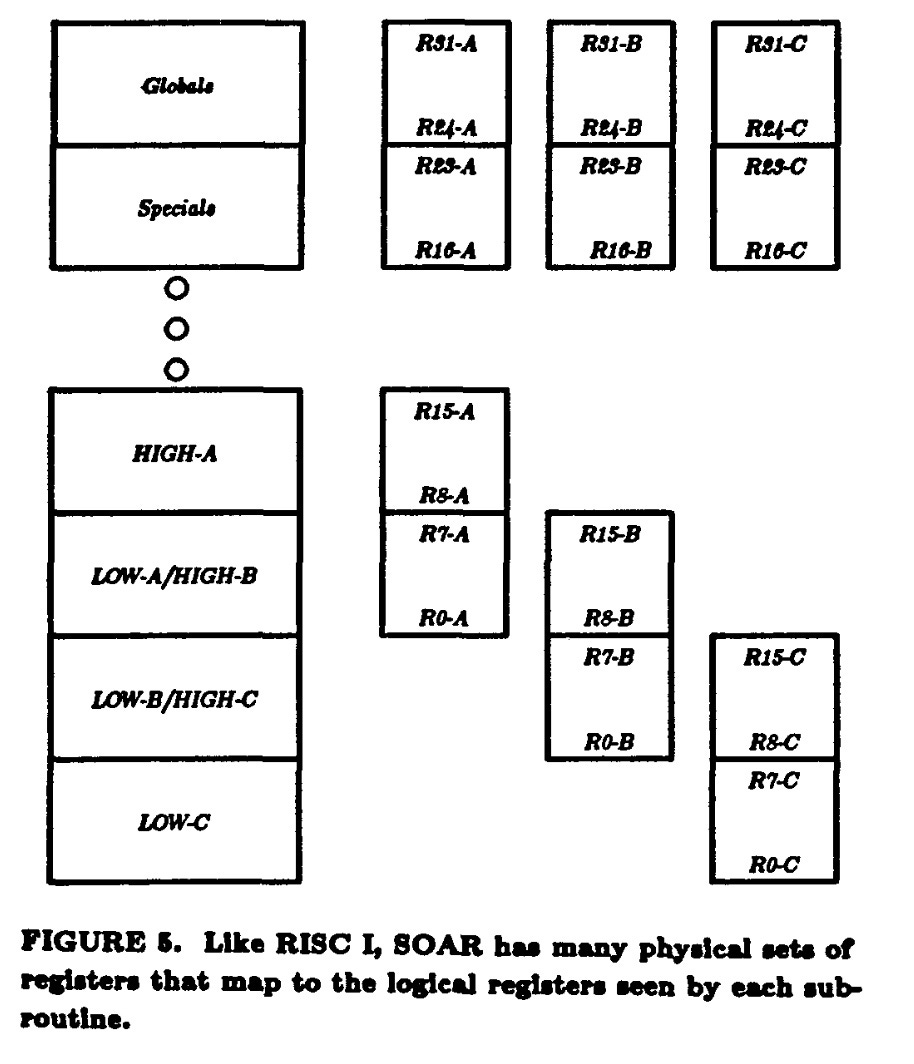
Let’s describe some of the basics of the SOAR architecture. It would have thirty-two 32-bit addressable registers. Like RISC-I it would have multiple physical sets of some of these registers arranged as ‘register windows’ with a total of seventy-two physical 32-bit registers. These would play a key role in accelerating Smalltalk execution.
Instruction Set
Consistent with other RISC designs of the time, it had a small instruction set with just twenty distinct instructions.
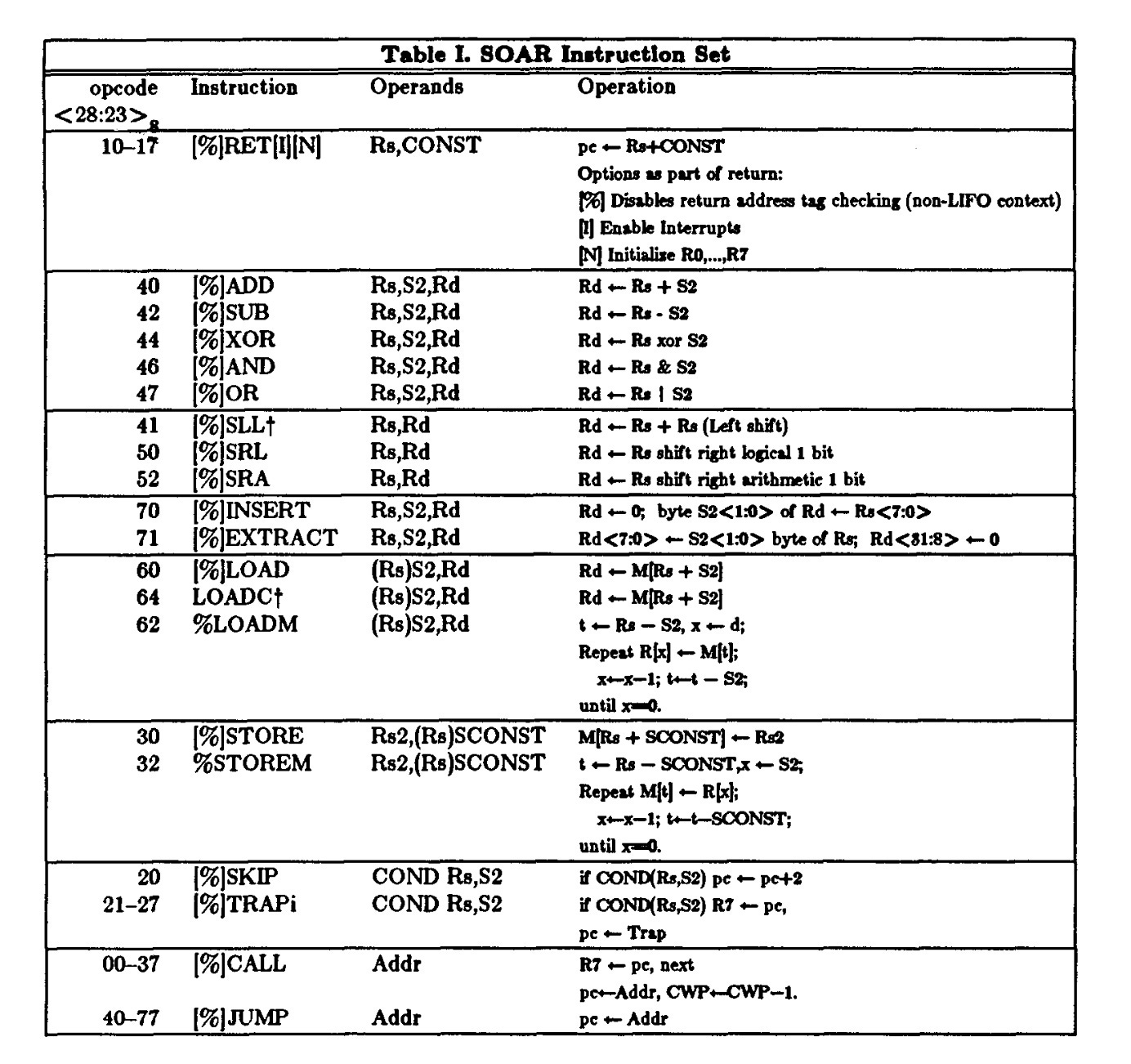
So far, in outline at least, this looks like a fairly standard simple RISC instruction set: SOAR had fewer instructions than RISC-1. As we’ll see later, though, there would be some crucial ways in which the SOAR architecture would depart from earlier RISC designs.
Instruction Encoding
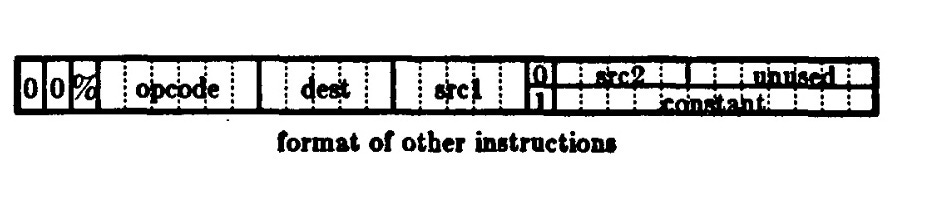
SOAR had extremely simple instruction encoding with just two 32-bit instruction formats. First, jumps and calls with a 1-bit ‘opcode’ for ‘jump’ or ‘call’ and a 28-bit target address.

Other instructions had a 6-bit opcode, a destination register, a source register, and either a second source register or an integer constant.
Faster Smalltalk
So far, so RISCy. But the SOAR project team didn’t just rely on the speed that RISC could deliver to speed up Smalltalk execution. They looked to adapt the architecture to mitigate some of the factors slowing Smalltalk execution.
The first optimization, though, followed on from the earlier Smalltalk-80 implementation on the VAX and didn’t need any changes to the basic RISC architecture.
Compiling Smalltalk-80 Bytecode
One of the critical decisions was that Smalltalk-80 bytecode would be compiled to SOAR machine instructions. The bytecode was for a virtual ‘stack-oriented’ machine. Common operations were performed by pushing values onto the stack and operations like arithmetic would then take place on values at the top of the stack. SOAR would compile these stack-based instructions into RISC register-based instructions.
The basic task of the compiler is to translate stack-oriented bytecodes into RISC-style loads, stores, and other register-based instructions.
Dynamic Typing & Polymorphism
The second optimization did require changes to the RISC architecture. The project team noted that:
Since Smalltalk is polymorphic and variable types are not known at compile time, it is never safe to generate integer instructions without runtime type checking. The virtual machine requires a dynamic method lookup on each operator, including '+’.
However, this dynamic method lookup is time-consuming. The SOAR team found that, for example, most instances of ‘+’ were integer additions, so they speeded up this operation by:
… assuming that all simple arithmetic operations (plus, minus, comparisons, etc.) will be performed only on integers. The compiler thus treats all such operations as if they were on integers, and generates integer code. If, say, an add instruction is initiated on two objects, and one or both of them turn out to be non-integers, the hardware will trap and transfer to a handler that will look up the correct method for the intended operation.
How was this implemented? The two values (for example) being added are 32-bit values in one of two formats: either a 31-bit integer or a 28-bit pointer - a 28-bit address pointing to the memory address where details of the object are stored.

SOAR’s hardware could identify when one of the values added was not an integer using the ‘tag’ information in the most significant bits of the 32-bit word.
When this happens it would perform a ‘trap’, and jump to a special subroutine that deals with the addition of values other than integers.
Object Management
Tags in pointers performed another crucial role: helping to streamline the management of Smalltalk objects. SOAR avoided the need for ‘reference counting’ where the Smalltalk system keeps track of how many times an object is referenced.
Instead, SOAR relies on an algorithm that classifies an object into one of multiple generations, and uses ‘tags’ in pointers to identify which generation and adds hardware support in the CPU to speed up the use of these tags.
… is to keep track of the 'age' of an object for efficient support of generation scavenging …. SOAR objects can be divided into four different 'tenure' groups, reflecting the number of scavenging operations that the object has survived.
Before we finish our discussion of tags, it’s worth noting that SOAR allowed the use of tagging, with the corresponding calls to traps, to be ‘turned’ off on an instruction-by-instruction basis. This meant that SOAR could easily be used to execute code generated by non-object-oriented languages such as C or Pascal.
Subroutine Calls
The Berkeley team had discovered that Smalltalk-80 programs spent a lot of their time making subroutine calls. RISC-I had included ‘register windows’, multiple sets of hardware registers, which could be switched between for a subroutine call, thus avoiding the need to save registers to memory. So this approach was also adopted in SOAR.
SOAR also sped up cases where registers did need to be saved to memory by adding instructions that would save multiple registers to memory:
Unlike RISC I, SOAR has load- and store-multiple instructions to speed register saving and in nine cycles (one instruction fetch and eight data accesses). Without them, eight individual instructions would be needed that consume sixteen cycles (eight instruction fetches plus eight data accesses).
Likewise, the RET instruction, which implemented the return from a subroutine, allowed the initialization of multiple registers in parallel:
Instead of initializing each register with a separate instruction at the beginning of each subroutine, SOAR exploits VLSI and initializes all the registers of a window in parallel.
Finally, SOAR also accelerated subroutine calls by caching call information.
We’ve just scratched the surface of SOAR’s features here. The papers linked at the end of this post give a lot more detail, especially the ‘SOAR Architecture’ paper which gives lots of detail on the hardware implementation of SOAR.
Simulated Performance
How well did these innovations work? One SOAR paper compared the performance on ‘micro-benchmarks’ of 68000 and VAX-11/780 Smalltalk-based systems with a simulated SOAR system and indicated significant expected performance improvements for SOAR when compared to each.3 SOAR couldn't match the Xerox Dorado, but on many benchmarks, it managed 50% or more of the performance of the much more expensive machine.

The Berkeley team would go on to fabricate physical SOAR devices in 1984:
The NMOS implementation of SOAR is 432 mils [11mm] wide, 320 mils [8.1mm] high, contains 35,300 [or 35,700 according to some sources] transistors … This chip uses the three-stage pipeline of RISC lI: instruction prefetch, execution, and write result.
Three SOAR Mysteries
Actual Performance and CMOS
SOAR was implemented in a 4-micron process and ran at 2.5MHz. Intriguingly, there seems to be no official record of the actual performance of SOAR. The SOAR papers also mention a CMOS version of the design but again there appears to be no further record of this. Perhaps a more informed reader can complete the record on each of these points?
iAPX432 Emulation!?
The SOAR Architecture paper includes an intriguing reference to (Intel) iAPX432 emulation mode.

However, this seems to be the sole reference to iAPX432 emulation in the SOAR papers. Again, perhaps a better-informed reader can add more context.
SOAR-ing Away?
SOAR, as had been the case with RISC-I and RISC-II, was a research project, undertaken by students with a tiny budget. Nonetheless, they delivered interesting results and real hardware that, on paper at least, was expected to outperform leading designs of the time.
The Berkeley team was hugely talented. I think that there is a wider point that emerges from this, though. The simplicity of the Berkeley RISC designs provided a powerful platform for innovation. It’s a superpower that continues today with RISC-V.
SOAR never led to a commercial product. In the late 1980s and early 1990s, object-oriented programming rose in popularity but in the shape of languages, such as C++ and Objective-C that compiled into machine code. Non-object-oriented C, the language used to implement Unix, became the target for early commercial RISC designs such as MIPS and SPARC. Faster microprocessors, enabled by Moore’s Law and Dennard Scaling, removed some of the pressure to accelerate common object-oriented operations.
But fast forward to 2020 when a (now deleted) tweet from Apple engineer David Smith confirmed dramatic speed-ups on, the then-new, Apple Silicon Macs for common object-oriented operations in Apple’s Smalltalk-influenced Objective-C language:
Fun fact: retaining and releasing an NSObject takes ~30 nanoseconds on current gen Intel, and ~6.5 nanoseconds on an M1
… and ~14 nanoseconds on an M1 emulating an Intel.
SOAR may be history now, but the search for ways of generating object-oriented language performance improvements goes on.
References and Further Reading
An Early History of Smalltalk
For more on the story of Smalltalk then Alan Kay’s An Early History of Smalltalk is a terrific read (hosted on Brett Victor’s website). Note that there is also a likely-to-be easier-to-read linked PDF version.
Architecture of SOAR: Smalltalk on a RISC
Smalltalk on a RISC (SOAR) is a simple, Von Neumann computer that is designed to execute the Smalltalk-80 system much faster than existing VLSI microcomputers.
https://dl.acm.org/doi/pdf/10.1145/773453.808182
SOAR: Smalltalk Without Bytecodes
We have implemented Smalltalk-80 on an instruction- level simulator for a RISC microcomputer called SOAR. Measurements suggest that even a conventional computer can provide high performance for Smalltalk-80 by aban- doning the 'Smalltalk Virtual Machine' in favor of com- piling Smalltalk directly to SOAR machine code, linearis- ing the activation records on the machine stack, eliminating the object table, and replacing reference counting with a new technique called Generation Scavenging.
https://dl.acm.org/doi/pdf/10.1145/28697.28708
SOAR Architecture
This document is the definition of the SOAR (Smalltalk on A RISC architecture and implementation, and is not meant to be the first exposure of a reader to SOAR, the RISC approach to architecture, or Smalltalk.
https://www2.eecs.berkeley.edu/Pubs/TechRpts/1985/CSD-85-226.pdf
Compiling Smalltalk-80 to a RISC
The Smalltalk On A RISC project at U.C. Berkeley proves that a high-level object-oriented language can attain high performance on a modified reduced instruction set architecture.
Performance analysis suggests that SOAR is not simple enough; several hardware features could be efficiently replaced by instruc- tion sequences constructed by the compiler.
https://dl.acm.org/doi/pdf/10.1145/36204.36192
An Object-Oriented Architecture
Note that this covers a wider range of Smalltalk-related research than just SOAR.
https://dl.acm.org/doi/pdf/10.5555/327010.327151
Smalltalk-80 to SOAR Code
This document describes the Smaltalk-80 to SOAR code translator. The first section discusses the implementation of the translator. Section two presents performance results for the translator. The third section describes issues in register allocation, one of the most important aspects of the translator. Section four deals with the experience of developing a moderate system in Smalltalk.
https://www2.eecs.berkeley.edu/Pubs/TechRpts/1986/CSD-86-297.pdf
Berkeley Smalltalk: Who Knows Where The Time Goes (on p189)
We have implemented the Smalltalk-80 virtual machine in the C programming language for the Digital Equipment Corp. VAX-11/780 under Berkeley Unix.
https://rmod-files.lille.inria.fr/FreeBooks/BitsOfHistory/BitsOfHistory.pdf
The first version of this post said that this work was funded by DARPA. DARPA did fund work on Smalltalk, including at UC Berkeley, but not as far as I can tell at Xerox PARC. Thanks to Paul McJones for the correction.
It was designed by Joan Pendleton, David Ungar, Shing Kong, Will Brown, Frank Dunlap, and Chris Marino, students of Professors David Hodges and David Patterson.
{kind=link}
Intriguingly the SOAR paper included a comparison with a reconfigured Intel iAPX432:
Alan Borning has projected that if the Intel iAPX-432, an object-oriented microprocessor were remicrocoded for Smalltalk-80, its performance would be about 20% of a Dorado.
NIce article.
A related anecdote: in the early 1990s I did some markreting consultancy for a company who attempted to commercialise a CPU in this vein: the Linn Rekursiv.
Linn was most famous for its ultra-high-end record players. They believed utterly in vertical integration: the record players were made in their factory, using custom tools, controlled by a unique ERP/MRP software system they had written, all coded in Smalltalk (or rather a unique , in-house, Smalltalk variant).
But on a VAX it ran s-l-o-w-l-y so obviously they designed their own ASIC/CPU chipset. Obviously...
And having designed it, got the few they needed fir their own in-house use they then decided to sell it externally, which is where I came in.
It was very clever: unified memory (RAM & HDD were a single addrees space), everything was an "object", tagged memory, hardware garbage collection.
It was also impossible to use, incredibly strange, almost undocumented, no faster than conventional CPUs by the time it was released, full of bugs and a "user hostile" commercial attitude ;)
Not surprisingly, it was not a success!
One of the main legacies of Smalltalk and SOAR was to get architects thinking about optimizations more broadly. You can see a lot of Smalltalk trickery in dynamic language implementations from Basic to Java to Python, as well as in how speculative hardware in CPUs work. The use of optimistic patterns not just for jumps but to enable dynamic typing to work efficiently really opened up possibilities. These techniques might have been invented anyway (LISP did originate some of the best work on pointers vs. values, and on GC), but Smalltalk was early, pure, in the right place at the right time, and attracted a lot of talent.